
Menschenleere Naturfotos auch an belebten Plätzen machen dank YOLOv7 und OpenCV.
Objektdetektion mit YoloV5 und Python
 Erfolgreiche "Bob-Detektion" durch ein mit YOLOv5 trainiertes neuronales Netzwerk.
Erfolgreiche "Bob-Detektion" durch ein mit YOLOv5 trainiertes neuronales Netzwerk.
Die schnelle Erkennung von Objekten in Fotos und Videos wird für bildverarbeitende Anwendungen immer wichtiger. So gibt es bereits eine Vielzahl von auf neuronalen Netzwerken basierenden Detektoren, die Objekte des täglichen Lebens wie Autos, Menschen, Hunde oder Katzen erkennen. Manchmal möchte man aber eigene Modelle trainieren. Wie das mit Python und YOLOv5 geht, erkläre ich hier, denn heute bauen wir einen Bob-Detektor.
Bob ist eine reiselustige Lego-Minifigur, von der ich jede Menge Fotos habe. Das ist für das Training das mit Abstand wichtigste. Wir werden den Detektor mit YOLOv5 antrainieren. YOLO ist der Name eines Algorithmus der, mittels neuronaler Netze Objekte in Bildern detektieren kann. Dieses englische Akronym steht für "You look only once" (übersetzt: "Du siehst nur einmal hin"). Es ist ein Hinweis darauf, dass der Algorithmus für eine erfolgreiche Detektion ein Bild nur einmal verarbeiten muss. YOLOv5 gehört aktuell zu den besten Objektdetektoren und ist einfach zu trainieren.
Bevor wir beginnen, sollten wir zunächst klären, was Objektdetektion leisten kann und was nicht. Für auf neuronalen Netzwerken basierende Detektionsaufgaben der maschinellen Bildverarbeitung gibt es drei verschiedene Arten von Algorithmen: Bildklassifikation, Objektdetektion und Bild- bzw. Instanzsegmentation.
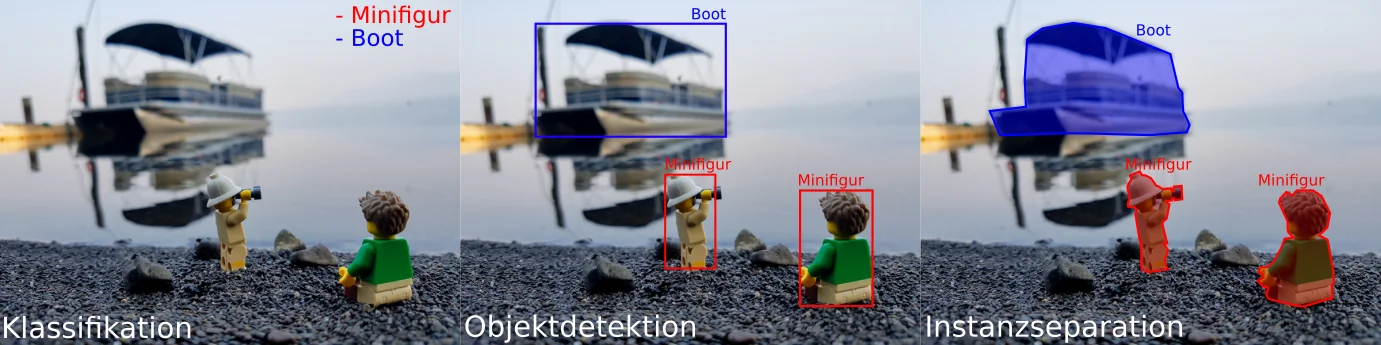 Verschiedene Aufgaben von, auf maschinellem Lernen basierenden Algorithmen.
Verschiedene Aufgaben von, auf maschinellem Lernen basierenden Algorithmen.
Klassifikation ist eine Aufgabe, bei der ein Algorithmus darauf trainiert wird zu erkennen, welche Objektklassen in einem Bild vorhanden sind. Klassifikation ist geeignet um zu prüfen, ob ein Bild bestimmte Objekte enthält. Die Position der Objekte wird nicht bestimmt. Ein Beispiel für eine Klassifikationsaufgabe ist die Geschlechtserkennung anhand von Fotos (siehe [2]).
Objektdetektion kombiniert die Klassifikation mit der Positionsbestimmung der Objekte. Gefundene Objekte werden durch Rechtecke markiert. Mittels Objektdetektion kann man beispielsweise Objekttracking, also Positionsverfolgung, implementieren. Der Bob-Detektor fällt in die Klasse der Objektdetektoren.
Bei der Bildsegmentierung wird ein Bild in Regionen mit polygonförmiger Umrandung unterteilt. Die Umrisse der Regionen werden Pixel für Pixel ermittelt. Die Regionen können verwendet werden, um räumliche Beziehungen der Objekte zueinander zu bestimmen oder sie können als Startregionen für weitergehende Objektdetektionen dienen. Im Bereich des autonomen Fahrens ist Instanzseparation beispielsweise notwendig, um den Verlauf von Straßen und Fußwegen zu erkennen.
Das Training beginnt mit der Erstellung eines Trainingsdatensatzes. Wie so oft in der Informatik, gilt auch hier der Spruch: Garbage In, Garbage Out! Übersetzt bedeutet das wörtlich: "Müll rein, Müll raus". Wenn die Eingangsdaten schlecht sind, wird auch das Ergebnis schlecht. Für das Training müssen dem Detektor Objekte aller Klassen (z.B.: Hunde, Katzen, Autos, Menschen) gezeigt werden. Das Anlernen erfordert daher eine Vielzahl von Bildern, in welchen die gewünschten Objekte abgebildet sind. Alle Vorkommen dieser Objekte müssen dann mit einer geeigneten Software markiert werden (z.B. labelimg).
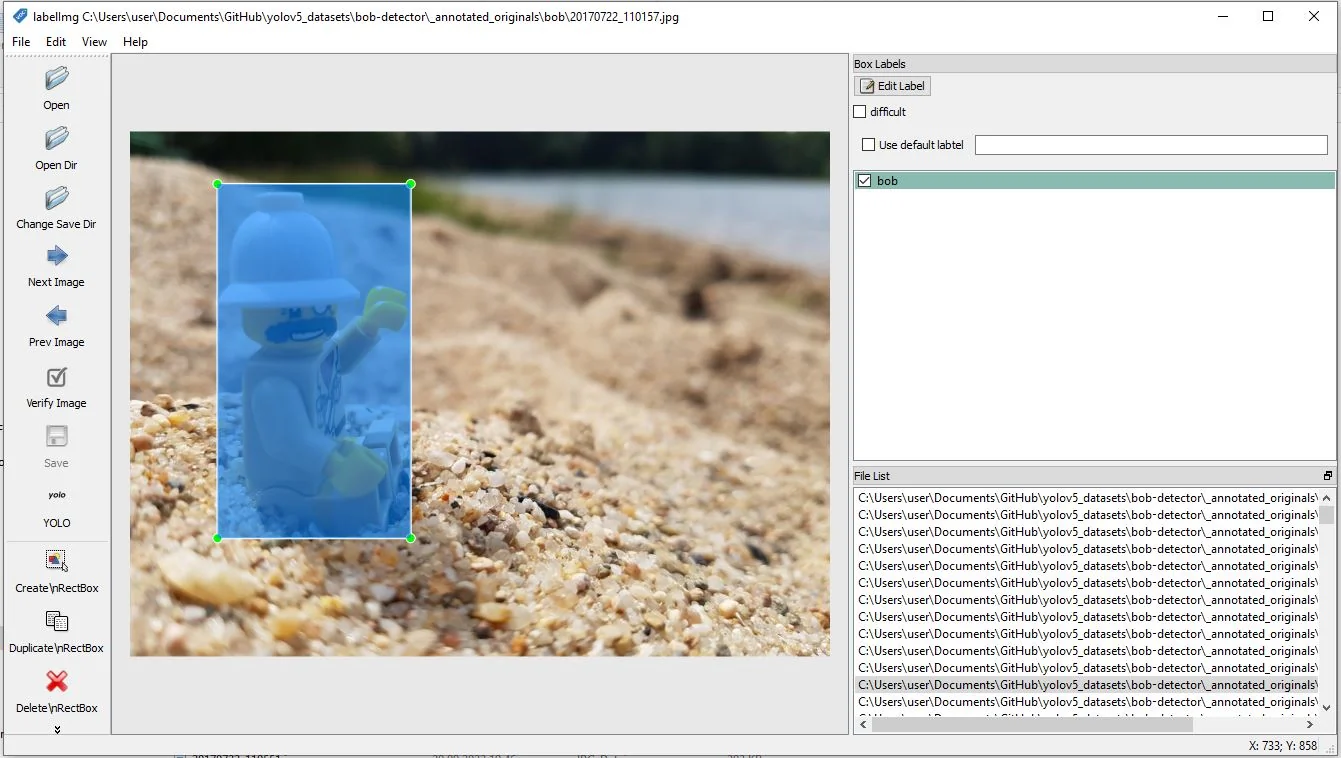 Das Markieren der Trainingsbilder erfolgt mit dem Programm labelimg. Um jedes Vorkommen des zu trainierenden Objektes
in den Bildern muss ein Rechteck gezogen werden. Es können beliebig viele Objekte aus verschiedenen Klassen markiert werden. Im Beispiel
trainieren wir nur eine Klasse namens "bob".
Das Markieren der Trainingsbilder erfolgt mit dem Programm labelimg. Um jedes Vorkommen des zu trainierenden Objektes
in den Bildern muss ein Rechteck gezogen werden. Es können beliebig viele Objekte aus verschiedenen Klassen markiert werden. Im Beispiel
trainieren wir nur eine Klasse namens "bob".
Ein Trainingsdatensatz besteht aus Trainingsbildern und Validierungsbildern. Trainingsbilder sind Bilder, die vom Algorithmus für das Training verwendet werden. Validierungsbilder dienen der Abschätzung der Qualität des Detektors während des Trainingsprozesses. Zu Trainings- und Validierungsbildern sollten Markierungsdateien existieren (Ausnahme: Hintergrundbilder). Das sind Textdateien, in der die Positionen und Größen aller im Bild enthaltenen Objekte aufgelistet sind.
Es ist wichtig auf eine möglichst große Varianz bei den Eingangsbildern zu achten. Diese sollten das zu trainierende Objekt aus vielen Blickwinkeln in verschiedenen Umgebungen bei unterschiedlichen Licht- und Wetterverhältnissen zeigen. Für Objekte im Freien sollten auch immer Bilder aus unterschiedlichen Jahreszeiten im Trainingspool sein. Die Trainingsbilder sollten, wenn möglich mit verschiedenen Kameras aufgenommen worden sein und sich in der Bildauflösungen voneinander unterscheiden. Ein Detektor für Autos sollte nicht ausschließlich mit Bildern aus einem Museum antrainiert werden. Am Ende könnte es sein, dass er nur Oldtimer oder Autos bei Kunstlicht erkennt oder dass er gar nicht auf Autos, sondern auf die Beschreibungstafeln davor trainiert wurde.
Für die Anzahl der Trainingsbilder gilt: Je mehr desto besser! Empfehlungen gehen dahin über 1500 Bilder pro zu trainierender Klasse zu verwenden und mehr als 10000 Instanzen pro Klasse zu trainieren. (siehe Regeln für Trainingsdatensätze) Es geht aber durchaus auch mit weniger, denn die Anforderungen an unseren Bob-Detektor sind überschaubar. Er soll nur eine einzige, sehr spezielle Minifigur erkennen. Für ein so eingeschränktes Problem kann man durchaus auch mit weniger Trainingsbildern beginnen.
 Beispielbild mit zwei Objektmarkierungen.
Beispielbild mit zwei Objektmarkierungen.
Die Bilder des Bob-Detektors wurden mit dem Programm labelimg annotiert. Mit diesem Programm kann man in einem Bild verschiedene Objektklassen mit Boxen markieren und diese Markierungen im YOLO-Format speichern. Das Markieren der Bilder ist der mit Abstand arbeitsintensivste Teil. Man muss hier sorgfältig arbeiten, denn die Qualität der Arbeit bestimmt die Qualität des fertigen Modells. YOLO erwartet die Markierungen in einer Textdatei mit dem gleichen Basisnamen wie die Bilddatei. Die Koordinaten werden relativ zu Bildbreite bzw. -Höhe angegeben. Die Werte liegen daher zwischen 0 und 1. Der Inhalt der Markierungsdatei des Bildes links sieht wie folgt aus:
0 0.6927759 0.6017316 0.1907467 0.5714285 0 0.3530844 0.5551948 0.1866883 0.4069264
Spalte 1: Objekt-Id
Spalte 2: X-Position der Markierungsbox
Spalte 3: Y-Position der Markierungsbox
Spalte 4: Breite der Markierungsbox
Spalte 5: Höhe der Markierungsbox
Um die Qualität der Trainingsdaten sicherzustellen, sollte man sich an folgende Regeln halten:
(Quelle: YOLOv5 Instruktionen auf GitHub und Annotating With Bounding Boxes: Quality Best Practices)
Um später Fehldetektionen zu vermeiden, sollte ein Datensatz bis zu 10% Hintergrundbilder enthalten. Das sind Bilder, in denen keines der zu trainierenden Objekte vorkommt. Diese Bilder reduzieren die Anfälligkeit des Modells im Bezug auf sog. "False Positives". So nennt man es, wenn der Detektor ein Objekt findet, das nicht im Bild vorhanden ist.
Es sollte unbedingt darauf geachtet werden, das wirklich keines der zu trainierenden Objekte in den Hintergrundbildern enthalten ist, auch nicht teilweise oder als Reflexion. Eine Bild von einem Baum, in dessen Hintergrund halb verdeckt ein Auto parkt, taugt nicht als Hintergrundbild für einen Fahrzeugdetektor! YOLOv5 wird Bilder im Trainingsordner, die keine Markierungsdatei haben automatisch als Hintergrundbilder behandeln.
Validierungsbilder unterscheiden sich prinzipiell nicht von Trainingsbildern. Es sind Bilder mit dazugehörenden Objektmarkierungsdateien. Ein Problem beim Training eines Objektdetektors ist das sogenannte "Overfitting". So bezeichnet man es, wenn der Detektor zu speziell auf die Trainingsbilder anspricht und nicht mehr gut Verallgemeinern kann. Beispielsweise könnte Bob in unserem Trainingsdatensatz einen Fleck auf dem Oberkörper haben. Im Falle von "Overfitting" könnte der Detektor diesen Fleck zu einen entscheidenden Merkmal machen und später nur noch auf Bilder mit diesem speziellen Defekt ansprechen.
Um Overfitting zu erkennen und zu vermeiden, benötigt man beim Training immer einen Bilddatensatz mit Validierungsbildern. Weil diese Bilder nicht in das Training des neuronalen Netzwerkes eingehen, sind sie für den Detektor neu und unbekannt. Der Algorithmus wird während des Trainings versuchen Objekte in den Validierungsbildern zu erkennen und seine Ergebnisse mit den hinterlegten Markierungen vergleichen. Wenn er merkt, dass die Erkennungswahrscheinlichkeit in den Validierungsdaten abnimmt, ist das ein Zeichen für beginnendes Overfitting. Der Algorithmus wird dann die Berechnung abbrechen, weil eine Fortsetzung nur zu einer Reduzierung der Allgemeingültigkeit des fertigen Detektors führen würde. 10-20% Der Bilder eines Trainingsdatensatzes sollten Validierungsbilder sein.
Nicht immer verfügt man über genügend Trainingsbilder. Daher ist es oftmals ratsam, die vorhandenen Bilder in leicht modifizierter Version mehrfach im Trainingspool zu verwenden. Im englischen bezeichnet man das als "Augmentation". Ob und welche Arten von Augmentation man verwendet, hängt davon ab, was der Detektor am Ende erkennen soll. Für den Bob-Detektor wird jedes Trainingsbild zusätzlich 3 mal um jeweils 90 Grad gedreht. Das Ziel ist eine sogenannte Rotationsinvarianz des Detektors. Er soll Bob auch erkennen, wenn er liegt, auf dem Kopf steht oder die Kamera einfach nur falsch gehalten wurde. Da die Trainingsdaten keine derartigen Bilder enthalten, werden sie im Rahmen der Augmentation künstlich erstellt.
 Der Inhalt des YOLO-Trainingsverzeichnisses nach Ausführung der Augmentation durch Bildrotation.
Der Inhalt des YOLO-Trainingsverzeichnisses nach Ausführung der Augmentation durch Bildrotation.
Mögliche Arten von Augmentationen sind:
YOLO wird verschiedene Arten der Augmentation während des Trainingsprozesses automatisch durchführen. Es kann aber trotzdem sinnvoll sein, den Trainingspool durch spezielle für das Problem passende Augmentationen manuell zu erweitern. In diesem Fall möchte ich die Rotationen nicht dem Zufall überlassen und wirklich jedes Bild in 4 Varianten im Trainingsdatensatz haben.
Für das Training muss YOLOv5 in einer Version mit GPU-Unterstützung installiert sein. Die Einrichtung von YOLOv5 wird in einem eigenen Artikel beschrieben. Zusätzlich zu YOLOv5 sollte der Beispieltrainingsdatensatz des Bob-Detektors von GitHub heruntergeladen werden. Im GitHub Projektverzeichnis existiert dann ein Archiv namens yolov5 und eines namens yolov5-bob-detector:
git clone https://github.com/beltoforion/yolov5-bob-detector # Trainingsbilder herunterladenWer jetzt direkt einen Bob-Detektor bauen will, kann das Skript "build_detector.ps1" ausführen.
.\build_detector.ps1Ich habe das Archiv so angelegt, dass man es für eigenen Projekte weiterverwenden kann. Für jedes Projekt sollte ein eigener Unterordner existieren. Der Ordner, mit dem wir arbeiten heißt "bob-detector". Darin befinden sich die Trainingsbilder, verteilt auf verschiedene Unterordner im Verzeichnis _annotated_originals. Das ist noch nicht das YOLOv5 Trainingsverzeichnis, denn das Projekt ist einfacher zu handhaben, wenn man verschiedene Objektklassen in eigenen Unterordnern verwalten kann. Um die Bilder in die YOLOv5 Trainingsverzeichnisse zu kopieren und gleichzeitig die Augmentation auszuführen muss man lediglich das Powershell-Skript "update_images.ps1" ausführen. Das wird von Skript "build_detector.ps1" automatisch gemacht.
.\update_images.ps1Für jedes zu trainierende YOLOv5-Modell muss eine Konfigurationsdatei existieren. Die Datei enthält die Pfade zu den Trainings und Validierungsbildern. Normalerweise sollten Trainings- und Validierungsbilder unterschiedlich sein. Wenn Bilder, die für Validierung verwendet werden, nicht im Trainingsdatensatz enthalten sind, wird Overfitting vermieden und die Modellqualität steigt. Da für das Training hier aber nur relative wenige Bilder vorliegen, wird auf einen separaten Validierungsdatensatz verzichtet.
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../yolov5-bob-detector/bob-detector # dataset root dir
train: images/train # train images (relative to 'path') 128 images
val: images/train # val images (relative to 'path') 128 images
test: # test images (optional)
# Classes
names:
0: bobWenn die Modelldatei erstellt wurde, kann das Training beginnen. Es wird mit dem Skript yolov5/train.py gestartet. Wir verwenden dieses Skript hier im Modus für "Tranfer-Learning". Das bedeutet, wir beginnen mit einem bereits existierenden Modell und nicht bei Null. Das ist für neue Detektoren mit nur wenigen Trainingsbildern die empfohlenen Vorgehensweise. Das existierende Modell wird im weights Parameter übergeben. Wir verwenden ein auf den COCO-Datensatz vortrainiertes YOLOv5 Modell. Der COCO-Datensatz enthält Alltagsbilder. Das Standard YOLO-Modell ist auf 80 Klassen wie Autos, Menschen, Hunde und Katzen trainiert. Für das Training des Bob-Detektors werden die Gewichte dieses existierenden Modells als Startpunkt verwendet.
python train.py --name 'bob-detector' --img 640 --batch 16 --epochs 200 --data bob-detector.yaml --weights yolov5m.pt # train the model
--name
Gibt den Namen des Modells an. Die Daten des fertigen Modells werden in einem Unterverzeichnis des runs Verzeichnisses abgelegt, das
diesen Namen trägt. Wird keine Name angegeben, dann verwendet YOLOv5 den Standardnamen 'exp{x}', wobei x eine Nummer ist.
--img
Gibt die intern von YOLOv5 verwendete Bildgröße an. Je größer diese ist, desto länger dauert die Berechnung des Modells.
Der Defaultwert ist 640. Höhere Werte erfordern deutlich mehr Grafikspeicher.
--epochs
Gibt die Anzahl der zu berechnenden Epochen an. In einer Epoche wird jeweils der gesamte Trainingsdatensatz
einmal hin und zurück durch das neuronale Netzwerk geleitet. Es wird empfohlen mindestens 300 Epochen rechnen zu lassen.
Je mehr Epochen, desto besser wird das Modell aber bei zu vielen Epochen kommt es irgendwann
zum Overfitting. Das Modell wird dann in seiner Allgemeinheit eingeschränkt und zu stark auf die
Trainingsdaten hin optimiert. YOLOv5 wird automatisch beendet, wenn es erkennt, das keine Modellverbesserung in
den letzten 100 Epochen aufgetreten ist.
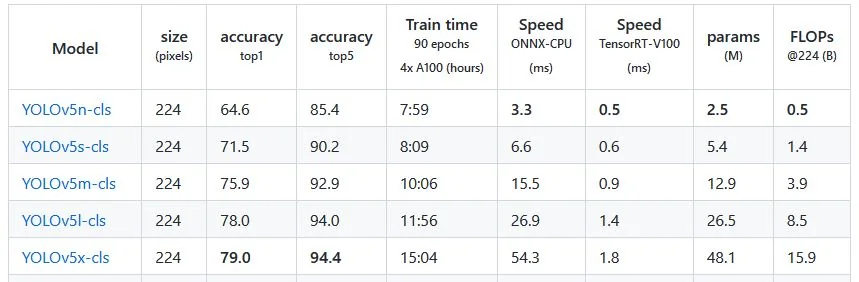 Verschiedene YOLO Modelle mit ihrer Netzwerkgrößen und anfallenden Rechenlasten. (Quelle: YOLOv5 v6.2 Release Notes)
Verschiedene YOLO Modelle mit ihrer Netzwerkgrößen und anfallenden Rechenlasten. (Quelle: YOLOv5 v6.2 Release Notes)
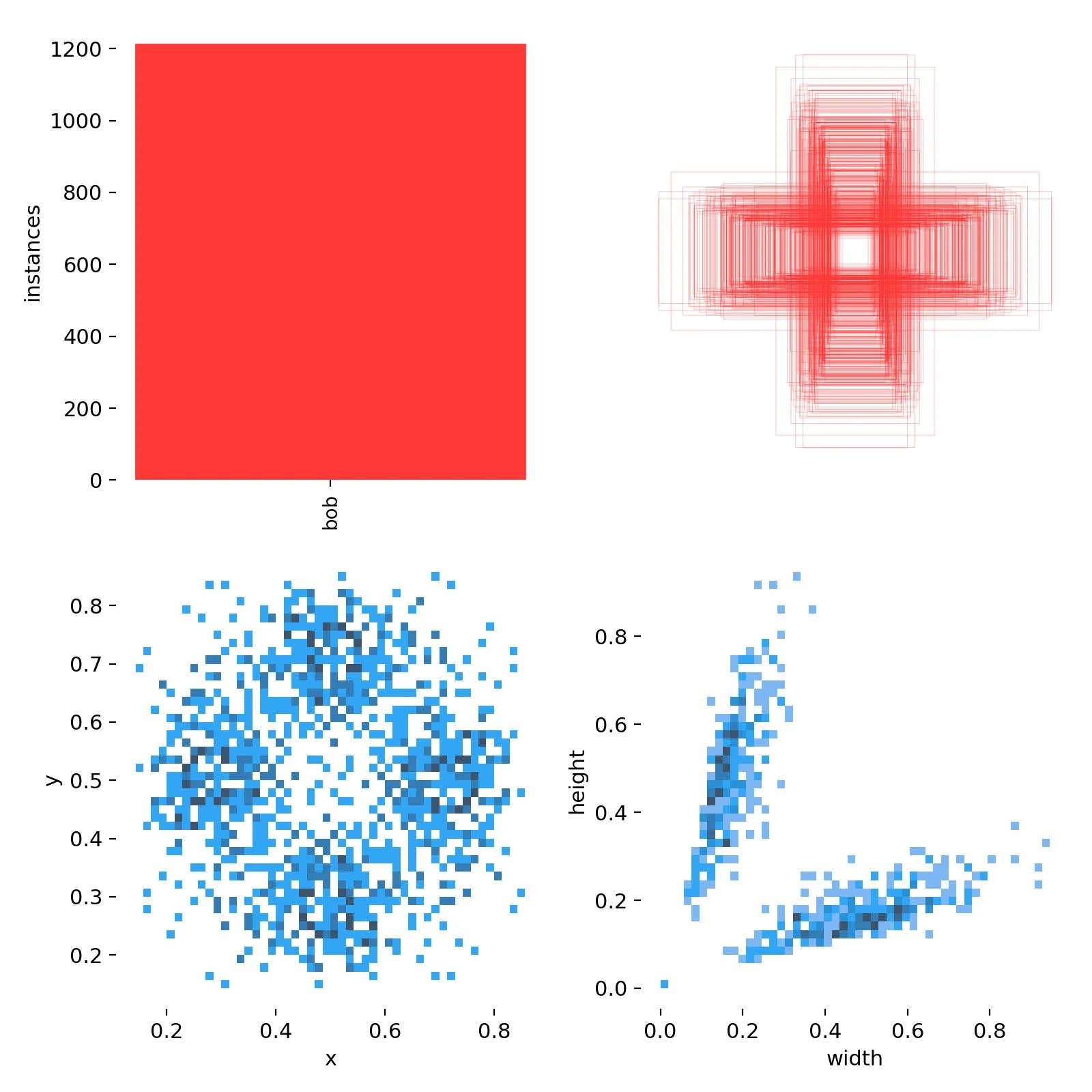 Statistiken zu den Trainingsdaten. Oben links: Gesamtanzahl an enthaltenen Objekten; Oben rechts: Größe aller Trainingsboxen; Unten Links: Positionsverteilung der Trainingsboxen; Unten Rechts: Größenverteilung der Trainingsboxen.
Statistiken zu den Trainingsdaten. Oben links: Gesamtanzahl an enthaltenen Objekten; Oben rechts: Größe aller Trainingsboxen; Unten Links: Positionsverteilung der Trainingsboxen; Unten Rechts: Größenverteilung der Trainingsboxen.
--batch
Die Gesamtanzahl an Trainingsbeispielen in einem einzigen Batch. Man kann nicht den gesamten Trainingsdatensatz auf einmal
in das neuronale Netzwerk geben. Dieser wird daher in Batches unterteilt. Dieser Parameter gibt die Batchgröße an.
Bei einer Anzahl von 1000 Trainingsbeispielen und einer Batchgröße von 100 muss der Algorithmus 10 mal
für eine Epoche iterieren.
--data
Gibt die Konfigurationsdatei des Modells an
--weights
Gibt an, mit welcher Modellgröße von YOLO gerechnet werden soll. Größere Modelle erzielen bessere Resultate, sind aber
bei der Detektion langsamer. Wenn man Smartphones als Zielplattform hat, sollte man eher kleinere Modelle verwenden.
Der Bob-Detektor wurde immer mit der mittleren Modellgröße berechnet.
Die Ausgabe erfolgt in einen Unterordner im runs/train Verzeichnis. Bereits während der Berechnung des Modells wird YOLOv5 die Ausgabe im Unterordner weights permanent aktualisieren. Man muss also nicht bis zum Ende warten, um ein funktionsfähiges YOLOv5 Modell zu erhalten. Die Datei best.pt im Ordner weights enthält das beste bislang berechnete Modell.
Der Ausgabeordner enthält ebenfalls Statistiken der Trainingsdaten. Ein Blick auf die grafisch aufbereiteten Trainingsdaten des Bob-Detektors zeigt, dass Bob im Mittel langgestreckt ist und es wird auch deutlich, dass bei der Augmentierung die Bilder um jeweils 90 Grad gedreht wurden. Die Modellpositionen häufen sich in 4, um 90 Grad gedrehten Gruppen. Es gibt nur wenige Bobs im Zentrum. Das liegt daran, das Bob bei Selfies immer darauf achtet im Goldenen Schnitt des Bildes zu sein. Er hat eben einen künstlerischen Anspruch an seine Fotos.
Der Vorgang die Fähigkeiten eines neuronalen Netzwerks an neuen Daten zu testen wird im englischen Inference genannt. Dafür benötigen wir Eingabebilder, die dem neuronalen Netzwerk unbekannt sind und einen einfachen Weg das Netzwerk an diesen Daten zu testen. YOLOv5 hat dafür ein Python-Skript namens detect.py. Den Bob-Detektor können wir mit folgendem Powershell Befehl testen:
python .\detect.py --name 'bob-detector' --augment --conf 0.25`
--weights '.\runs\train\bob-detector\weights\best.pt'`
--source '..\yolov5-bob-detector\bob-detector\images\test\'
--augment
Aktiviert Test-Time-Augmentation (TTA). Wenn dieser Parameter angegeben wird, werden die Testbilder bei der Suche "augmentiert".
Das bedeutet sie werden zusätzlich horizontal gespiegelt und es wird mit drei verschiedenen Bildauflösungen gesucht. Das Gesamtergebnis setzt
sich aus Detektionsergebnissen in den augmentierten Bildern zusammen. Augmentation verlangsamt die Detektion um Faktor 2 bis 3.
--conf
Gibt den einen Konfidenzschwellwert an, unterhalb dessen gefundenen Objekte ignoriert werden.
--name
Gibt einen Namen für das Datenverzeichnis des Tests an. Die Ergebnisse werden in einem Unterverzeichnis des runs Ordners abgelegt.
Wird keine Name angegeben, so verwendet YOLOv5 den Standardnamen 'exp{x}', wobei x eine Nummer ist.
--source
Pfad zum Verzeichnis mit den Testbildern und Videos. Wenn dieser Parameter fehlt werden die Testbilder bzw. Videos im
yolov5/data/images Unterordner gesucht.
--weights
Gibt den Pfad zu der Datei mit den Gewichten des zu testenden Modells an (*.pt-Datei).
Die Ergebnisse werden in einem Unterordner im Verzeichnis yolov5\runs\detect abgelegt. Wie man in folgendem Video sieht, funktioniert der Bob-Detektor sehr gut. Wenn er das nicht täte, müsste man Fotos, bei denen er versagt in den Trainingsdatenpool aufnehmen und das Modell neu berechnen.
 Der Bob-Detektor wurde nur auf Bob trainiert und ignoriert andere LEGO Minifiguren konsequent.
Der Bob-Detektor wurde nur auf Bob trainiert und ignoriert andere LEGO Minifiguren konsequent.
Menschenleere Naturfotos auch an belebten Plätzen machen dank YOLOv7 und OpenCV.

Simulation von Wellen durch lösen der 3D-Wellengleichung mittels finiter Differenzenmethode.

John Conway's Spiel des Lebens ist ein zellularer Automat, in dem aus einfachen Regeln komplexe Strukturen entstehen.
Berechnung von N-Körperproblemen mit dem Barnes-Hut Algorithmus.