
Rendern von Spiralgalaxien.

Atemberaubende Zoom-Animationen mit generativer KI und "outpainting" erstellen
 Eine Serie von drei Bildern, die von einer generativen KI mit Outpainting erstellt wurden.
Eine Serie von drei Bildern, die von einer generativen KI mit Outpainting erstellt wurden.
2022 und 2023 werden als die Jahre in Erinnerung bleiben, in denen generative Künstliche Intelligenz den Mainstream erreichte. Insbesondere Text-zu-Bild-Generatoren haben den Prozess der Bilderstellung von der Notwendigkeit entkoppelt künstlerisches Talent zu haben. Dadurch kann nun jedermann beeindruckende Bilder generieren. Programme wie Midjourney, Stable Diffusion, Dall-E 2 oder Adobes Firefly bieten die Möglichkeit, digitale Kunstwerke aus Textvorgaben zu erstellen. Ein Streifenhörnchen als Jedi-Ritter? Kein Problem. Eine Frau in einem Kleid aus Rauch? Leicht. Ein Astronaut auf dem Mars, der einen Vulkan betrachtet? Schon fertig.
 KI-generiertes Bild (Midjourney); Prompt: "A chipmunk as a Jedi Knight."
KI-generiertes Bild (Midjourney); Prompt: "A chipmunk as a Jedi Knight."
 KI-generiertes Bild (Midjourney); Prompt: "Portrait of a woman in a long flowing dress made up of smoke."
KI-generiertes Bild (Midjourney); Prompt: "Portrait of a woman in a long flowing dress made up of smoke."
 KI-generiertes Bild (Midjourney); Prompt: "An astronaut is standing on Mars watching the eruption of a volcano."
KI-generiertes Bild (Midjourney); Prompt: "An astronaut is standing on Mars watching the eruption of a volcano."
Ein Anwendungsfall für diese Bildgeneratoren ist "Content-Aware-Fill". Dabei werden fehlende Teile eines Bildes auf der Grundlage der verfügbaren Bilddaten ergänzt. Dies wurde zuvor algorithmenbasiert durchgeführt, zum Beispiel in Adobe Photoshop. Die neuen KI-basierten Ansätze sind leistungsstärker, weil die KI angewiesen werden kann, die Lücken in einem Bild mit bestimmtem Inhalt zu füllen. Wenn man beispielsweise ein Foto von einem Gebäude macht und später feststellt, dass die Spitze des Gebäudes abgeschnitten wurde, dann kann man jetzt künstliche Intelligenz verwenden, um die fehlenden Teile des Bildes zu ergänzen. Es wird nicht genau der Originalinhalt sein, aber es wird gut genug ersetzt, dass das menschliche Auge den Unterschied nicht erkennen kann. Das wird auch als "Outpainting" bezeichnet.
Man kann Outpainting auch verwenden, um wiederholt aus einem Bild herauszuzoomen und die KI den neu entstandenen leeren Raum füllen zu lassen. Führt man dies mehrfach durch, kann man die so entstandene Bildsequenz zu einem Video zusammenfügen. Das Ergebnis wird wie ein "unendlicher Zoom" aussehen. Dieser Artikel zeigt wie das funktioniert.
Ein "unendlicher" Zoom, erstellt durch eine Sequenz von KI-generierten Bildern.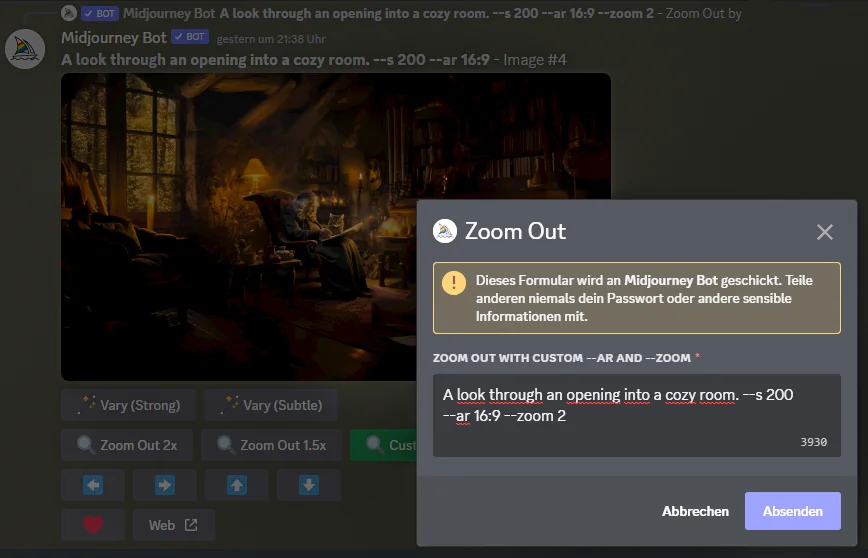 Outpainting und Re-Prompting können mit der "Custom Zoom"-Funktion von Midjourney durchgeführt werden.
Outpainting und Re-Prompting können mit der "Custom Zoom"-Funktion von Midjourney durchgeführt werden.
Vor Beginn wird eine Reihe von Bildern benötigt, die durch KI-Outpainting erzeugt wurden. Hier wurden sie von Midjourney erstellt. Midjourney ist ein kommerzieller Text-To-Image Dienst, der über einen Discord-Chatbot zugänglich ist. Der Befehl zum Starten der Bildgenerierung lautet /imagine. Dieser Befehl öffnet ein Textfeld, in das die Beschreibung des Bildes in englischer Sprache eingegeben werden kann. Wie beginnen mit dem letzten (innersten) Bild der Zoom Serie und starten mit dem Prompt:
A cozy room with a chair standing by a fireplace. An old woman is sitting in the chair reading a book. A black cat is sitting in front of the fire place. --s 200 --ar 16:9
Auf den Promot folgen Befehle, die das Seitenverhältnis des Ausgabebildes festzulegen und ein Parameter der die Stärke der "Stilisierung" definiert. Dieser Parameter gibt an, wie viel künstlerische Freiheit Midjourney bei der Verarbeitung der Aufforderung haben soll.
Sobald das erste Bild generiert ist, kann man die Funktion "Custom Zoom" verwenden, um aus dem Bild herauszuzoomen. Ein Dialog ermöglicht es dabei, den Prompt anzupassen. Für die spätere Animation ist es ist wichtig, für alle Bilder den gleichen Zoomfaktor zu verwenden.
Es ist ratsam, den Prompt regelmäßig zu ändern, um so Szenenübergänge zu schaffen. Ein Szenenübergang setzt einen neuen visuellen Rahmen. Man kann zum Beispiel mit dem Prompt "Ein Auto vor einem Haus" beginnen. Diesen wiederholt man einmal für ein zweites Bild und ändert ihn dann in "Ein gerahmtes Bild von einem Auto vor einem Haus.". Man befindet sich jetzt nicht mehr in einer Straßenszene, sondern in einem Wohnzimmer. Man könnte diesen Prompt für ein weiteres Bild verwenden um dann zu folgendem Prompt überzugehen: "Ein Wohnzimmer, das durch ein Portal zu einer anderen Dimension gesehen wird". Jetzt befindet man sich in einem Fantasy-Setting. Die Möglichkeiten sind endlos.
Das folgende Beispiel zeigt die Evolution der Prompts einer Szene:
A cozy room with a chair standing by a fireplace. An old woman is sitting in the chair reading a book. --s 200 --ar 16:9
A cozy room with a chair standing by a fireplace. An old woman is sitting in the chair reading a book. --s 200 --ar 16:9 --zoom 2
A look through an opening into a cozy room. --s 200 --ar 16:9 --zoom 2
A cosy room seen through a rectangular mirror with an ornate frame. --s 200 --ar 16:9 --zoom 2
A fairy in a white dress standing right to a mirror. --s 200 --ar 16:9 --zoom 2
A fairy in a white dress standing right to a mirror. --s 200 --ar 16:9 --zoom 2
A fairy in a white dress standing right to a mirror. --s 200 --ar 16:9 --zoom 2
A portal into another dimensions. Butterflies all over the place. --ar 16:9 --zoom 2
An eye shaped portal into another dimension. Butterflies all over the place. --ar 16:9 --zoom 2
An eye shaped portal into another dimension. Butterflies all over the place. --ar 16:9 --zoom 2
A glass sphere. --ar 16:9 --zoom 2
A glass sphere on top of a wooden table. --ar 16:9 --zoom 2
Two swordmasters facing one another in a room with a wooden floor. --ar 16:9 --zoom 2
Das Ergebnis dieser Promptserie ist hier dargestellt. Der nächste Schritt besteht darin, diese Bildsequenz in ein Zoom-Video umzuwandeln, bei dem entweder hinein- oder herausgezoomt werden kann.
 Ergebnis einer Zoom-Bildserie, die von Midjourney generiert wurde.
Ergebnis einer Zoom-Bildserie, die von Midjourney generiert wurde.
Die nächste Aufgabe besteht darin, die Bildserie zu ordnen. Das kann man manuell tun, indem die Dateinamen vereinheitlicht und mit aufsteigenden Framenummern versehen werden. Man beginnt dabei mit dem letzten Bild der Serie. Anschließend müssen die Bilder in eine Videobearbeitungssoftware importiert werden. Dort werden sie angeordnet und es kann hineingezoomt werden. Das ist ein mühsamer und arbeitsintensiver Prozess, denn Midjourney wird einige Schwierigkeiten bereitet. Die Bilder sind nicht perfekt ausgerichtet und es kann geringfügige Variationen des Bildinhaltes an den Kanten der Bilder geben. Es ist nicht unmöglich, das manuell zu machen aber es ist viel Arbeit.
Ich habe es nicht geschafft, aber ich bin kein Videobearbeitungsprofi. Ich bin jedoch ein Programmierer, der gerne Dinge automatisiert. Daher habe ich ein Skript geschrieben, um den gesamten Prozess zu vereinfachen. Das Skript verwendet Python und die OpenCV Bibliothek, um die Bilder zu sortieren, auszurichten, eventuelle Verschiebungen auszugleichen und dann eine mp4-Videosequenz zu erstellen. Man muss nur die Bilder bereitstellen, dem Skript den Zoomfaktor mitteilen und dieses erledigt den Rest. Das Skript ist auf GitHub verfügbar:
Zum Endlos-Zoom-Generator auf GitHub
Um das Programm verwenden zu können, muss Python auf dem System installiert sein. Ist das der Fall, dann kann man es von GitHub herunterladen oder mit Git auschecken. Mit dem Betriebssystem Linux geht das wie folgt:
git clone https://github.com/beltoforion/AI-Infinite-Zoom-Generator.git
cd ./AI-Infinite-Zoom-Generator/
pip install opencv-pythonIch stelle hier einige Beispielsequenzen bereit, mit denen der Videogenerator getestet werden kann. Diese Archive sollten im Ordner des Zoomgenerators ausgepackt werden:
Jetzt kann das Skript gestartet werden. In folgendem Minimalbeispiel gibt die Option "-as" an, dass die Bilder automatisch sortiert werden sollen. Diese Option kann weggelassen werden, wenn die Bilder bereits manuell sortiert wurden. Die weiteren Optionen "-i" und "-o" geben den Eingabeordner und den Namen der Ausgabedatei an.
python3 ./infinite_zoom.py -as -i ./sample_fairytale -o video.mp4Beispiel für das speichern der Einzelframes:
python3 ./infinite_zoom.py -as -i ./sample_fairytale -o myframes/Folgende Tabelle enthält eine vollständige Liste aller Kommandozeilenoptionen.
| Parameter | Beschreibung |
|---|---|
| -as | Eingabebilder automatisch sortieren. Wenn diese Option verwendet wird, findet das Skript die richtige Reihenfolge selbst heraus. Dies kann etwas Zeit in Anspruch nehmen. |
| -dbg | Debug-Overlays anzeigen. Diese Option blendet Debug-Overlays im fertigen Video ein. |
| -fps | Gibt die Framerate des Ausgabevideos an. Diese option hat nur Sinn, wenn die Ausgabe eine Videodatei ist. |
| -i | Pfad zum Ordner mit den Eingabebildern. |
| -o |
Name der Ausgabevideodatei oder des Ausgabeverzeichnisses. Hier kann entweder der Name eine mp4-Datei (inklusive der mp4 Endung) oder der Name eines zu erstellenden Ausgabeverzeichnisses angegeben werden. Wird ein Verzeichnisname angegeben, so erfolgt nicht die Ausgabe in Form von Einzelframes im PNG-Format und nicht als Video. Beispiele:
|
| -rev | Dreht die Zoomrichtung des Ausgabevideos um. Standardmäßig wird hineingezoomt, wenn diese Option gesetzt ist, wird herausgezoomt. |
| -zc | Bilder werden auf diesen Faktor beschnitten. Der Wert muss zwischen 0.1 und 0.95 liegen. Midjourney nimmt sich einige Freiheiten bei der Komposition im Randbereich zwischen zwei Zoombildern. Diese stimmen möglicherweise nicht perfekt überein. Weitere Informationen darüber gibt es im Abschnitt zur Behebung von Bildverschiebungen und Inhaltsvariationen. |
| -zf | Zoomfaktor für die Erstellung der ausgegebenen Bildsequenz. Bei durch Midjourney erstellte Bildsequenzen sollte entweder "2" oder "1.33" verwendet werden. Midjourney gibt fälschlicherweise an, dass der niedrige Zoomfaktor 1.5 ist. Tatsächlich beträgt er jedoch nur 1.33. |
| -zs | Anzahl der Zoomschritte für den Übergang zwischen zwei Folgebildern. Die Gesamtanzahl der Bilder im endgültigen Video beträgt number_of_images * mumber_of_zoom_steps |
Werfen wir eine Blick hinter die Kulissen und betrachten, wie das Skript funktioniert. Die erste Aufgabe besteht darin, die Bilder zu sortieren, danach werden die Zoomschritte berechnet und zu guter Letzt werden die Bilder ausgerichtet, zugeschnitten und abschließend zu einem Video zusammengefügt.
Die automatische Sortierung erfolgt mit Hilfe von OpenCV's Template Matching in Kombination mit einem normalisierten Kreuzkorrelationsalgorithmus. Jedes Bild wird mit einer verkleinerten Version aller anderen Bilder kreuzkorreliert. Dies ist im Video unten zu sehen. Das Originalbild wird in der linken oberen Ecke angezeigt. Die verkleinerten Versionen der anderen Bilder, die Kandidaten für das Vorgängerbild in der Zoomreihe sind, werden in der unteren linken Ecke angezeigt. Das bisher am besten passende Bild wird in der rechten oberen Ecke angezeigt. Es ist der wahrscheinlichste Vorläufer des aktuellen Bildes.
Unten rechts ist das Ergebnis der normalisierten Kreuzkorrelation dargestellt. Die Helligkeit an einem Punkt diese Bildes gibt an, wie gut die beiden Bilder übereinstimmen, wenn die verkleinerte Version an diese Position verschoben wird. Je heller der Punkt, desto besser die Übereinstimmung. Theoretisch sollte das resultierende Kreuzkorrelationsbild zweier Folgebilder der Serie einen hellen weißen Punkt in der Bildmitte aufweisen. Nach diesem Punkt suchen wir. Die Größe des Kreuzkorrelationsbildes ist kleiner als das Originalbild, da die Kreuzkorrelation zwischen zwei Bildern nur berechnet werden kann, wenn sich beide Bilder vollständig überlappen. Sie kann also nicht an den Rändern berechnet werden.
Algorithmus zum finden der Bildreihenfolge durch "Template Matching". Das erste Bild der Serie wird bei der 7 Sekunden Marke bearbeitet. Dieses Bild hat keinen Vorläufer, weswegen der Score-Wert des besten Matches (oben rechts) lediglich 0.54 beträgt. Ein solcher niedriger Wert wird als Indikator für das erste Bild der Sequenz gewertet.Nach Durchlaufen dieses Algorithmus kennen wir das Nachfolgebild zu jedem Bild in der Serie. Es bleibt nur noch das Erste und das Letzte Bild zu identifizieren. Das erste Bild zeichnet sich dadurch aus, dass es nicht als Nachfolger eines anderen Bildes identifiziert werden konnte. Das letzte Bild hat kein anderes Bild, das einen hohen Kreuzkorrelationswert mit ihm aufweist.
Sobald die Bilder sortiert sind, kann die Zoomanimation berechnet werden. Der Zoom beginnt mit dem letzten Bild in der Sequenz. Dieses Bild wird zu Beginn im Vollbildmodus angezeigt. Der Zoomfaktor beträgt daher 1. Das nächste Bild in der Serie wird dann um den Serien-Zoomfaktor verkleinert und mittig über das Erste gelegt. Wenn der Serien-Zoomfaktor 2 war, ist der initiale Zoomfaktor des inneren Bildes 1/2. (entspricht eins geteilt durch den Serien-Zoomfaktor) Überlagert man beide Bilder, so sollte nicht sofort erkennbar sein, wo das eine endet und das andere beginnt, da beide die gleiche Szene zeigen. Theoretisch unterscheiden sie sich ja nur in Ihrer Auflösung.
Nun müssen beide Bilder allmählich vergrößert werden, bis der Zoomfaktor des inneren Bildes 1 erreicht und es den Bildschirm komplett ausfüllt. Der Zoomfaktor des äußeren Bildes beträgt dann 2, was auch der Serien-Zoomfaktor der Sequenz ist. Danach wird das nächste Bild in der Mitte eingefügt und der Vorgang wiederholt. Das Zoomen erfolgt durch wiederholtes Skalieren beider Bilder mit dem gleichen Faktor, bis das innere Bild den Bildschirm komplett ausfüllt.
Der Kern der Zoomschleifenimplementierung in Python ist unten dargestellt. Es werden die OpenCV-Funktionen getRotationMatrix2D und warpAffine verwendet, um den Zoomeffekt zu erzeugen.
# compute step size for each partial image zoom. Zooming is an exponential
# process, so we need to compute the steps on a logarithmic scale.
f = math.exp(math.log(self.__param.zoom_factor)/zoom_steps)
# copy images because we will modify them
img_curr = imgCurr.copy()
img_next = imgNext.copy()
# Do the zoom from one image to the next
for i in range(0, zoom_steps):
zoom_factor = f**i
# zoom, the outter image
mtx_curr = cv2.getRotationMatrix2D((cx, cy), 0, zoom_factor)
img_curr = cv2.warpAffine(imgCurr, mtx_curr, (w, h))
# zoom the inner image, zoom factor is by the image series
# zoom factor smaller than that of the outter image
mtx_next = cv2.getRotationMatrix2D((cx, cy), 0, zoom_factor/self.__param.zoom_factor)
img_next = cv2.warpAffine(imgNext, mtx_next, (w, h))
...Reden wir kurz über die Berechnung der Zoomschrittweite, da diese nicht für jeden offensichtlich sein dürfte. Für den Übergang zwischen zwei Bildern beginnen wir immer mit dem äußeren Bild, das anfänglich den Zoomfaktor 1 hat. Dieser Faktor wird schrittweise erhöht, bis er den Wert 2 erreicht (den Serien-Zoomfaktor). Das innere Bild beginnt mit dem Zoomfaktor 1 geteilt durch den Serien-Zoomfaktor und endet mit dem Zoomfaktor 1 (Vollbild). Der Übergang soll in n Schritten erfolgen. Wir müssen den Wert von f, dem Zoomschrittmultiplikator, berechnen.
\begin{align} z_0 & = 1 \nonumber\\ z_n & = z_0 * f^n = f^n = 2 \end{align}Der Zoomfaktor \(z_0\) des ersten Schritts beim Übergang zwischen zwei Bildern ist immer 1. Nach \(n\) Schritten beträgt der Zoomfaktor \(z_n\)=2. Das n-Fache Herauszoomen mit dem Faktor f ist dasselbe wie das Multiplizieren des anfänglichen Zoom-Faktors mit \(f^n\). Den Zoomfaktor \(f\) kann man berechnen, indem man die Gleichung nach \(f\) auflöst. Für einen Serien-Zoomfaktor von 2 ergibt sich:
\begin{equation} f = e^{\frac{log(2)}{n}} \end{equation}Schauen wir uns ein konkretes Beispiel aus einer Sequenz von 6 Bildern an, die von Midjourney mit einem Serien-Zoomfaktor von 2 generiert wurden.
Die Animation funktioniert nicht richtig, weil die Übergänge zwischen den Bildern nicht fließend sind. Die Ursache liegt daran, dass Midjourney die Bilder nicht immer korrekt zentriert.Fällt etwas auf? Die Bildübergänge sind überhaupt nicht nahtlos! Der Grund dafür ist, dass Midjourney die Zoom-Bilder nicht immer an der richtigen Position generiert. Diese können leicht gegeneinander verschoben sein!
Die folgenden Bilder zeigen typische Inkonsistenzen in Sequenzen, die mit Midjourney generiert wurden. Links sind zwei aufeinanderfolgende Bilder einer Zoomsequenz in Überlagerung zu sehen. Das zweite Bild wurde verkleinert und an die Position verschoben, an der es am besten zum ersten passt. Es gibt einen leichten Versatz zwischen den Positionen der beiden Bilder.
Das rechte Bild zeigt geringfügige Variationen des Inhalts am Rand der Szene. Bild 1 wurde erstellt, indem aus Bild 2 herausgezoomt wurde. Dabei wurde der Prompt verändert, was zu leichten Modifikationen am Bildrand geführt hat. So waren weder der Bart noch der Holztisch bei der Erstellung von Bild 2 vorhanden.
 Zwei aufeinanderfolgende Bilder einer Zoomsequenz, die von Midjourney generiert wurden. Das zweite Bild ist verkleinert und wurde
an die Position verschoben, an der es am besten zum ersten Bild passt. Es ist eine Verschiebung zwischen dem roten und dem grünen
Kreuz erkennbar. Die beste Übereinstimmung befindet sich nicht in der Mitte des ersten Bildes, sondern leicht darunter!
Zwei aufeinanderfolgende Bilder einer Zoomsequenz, die von Midjourney generiert wurden. Das zweite Bild ist verkleinert und wurde
an die Position verschoben, an der es am besten zum ersten Bild passt. Es ist eine Verschiebung zwischen dem roten und dem grünen
Kreuz erkennbar. Die beste Übereinstimmung befindet sich nicht in der Mitte des ersten Bildes, sondern leicht darunter!
 Es besteht auch eine Inhaltsabweichung zwischen den beiden Bildern. "Image 1" wurde aus "Image 2" durch Herauszoomen erzeugt.
Zum Zeitpunkt der Erstellung von "Image 2" waren weder der Bart noch der Tisch in der Szene vorhanden. Beide Elemente erschienen
erst nach Änderung des Prompts.
Es besteht auch eine Inhaltsabweichung zwischen den beiden Bildern. "Image 1" wurde aus "Image 2" durch Herauszoomen erzeugt.
Zum Zeitpunkt der Erstellung von "Image 2" waren weder der Bart noch der Tisch in der Szene vorhanden. Beide Elemente erschienen
erst nach Änderung des Prompts.
Um die Verschiebung zu korrigieren, wird das innere Bild nicht in der Mitte des Äußeren eingefügt, sondern an der Stelle, an der es am besten passt. Diese Position wird mit Hilfe von OpenCV Template-Matching ermittelt. Beide Bilder werden dann bei jedem weiteren Zoomschritt leicht zur wahren Mitte hin verschoben. Verwendet das Skript beispielsweise 100 Zwischenschritte, so wird die Verschiebung im ersten Schritt ermittelt und dann im Verlauf der nächsten 99 Schritte stückweise korrigiert. Wenn das innere Bild das gesamte Sichtfeld abdeckt, ist die Verschiebung kompensiert.
Die Behebung der Inhaltsabweichung ist einfacher. Das Skript schneidet einfach das zweite Bild mit einem, vom Benutzer definierten, Crop-Faktor zu. Dadurch ignoriert der Algorithmus die Inhaltsabweichung im Inneren Bild und nimmt stattdessen die Bilddaten des Äußeren. Der Nachteil besteht darin, dass das verfügbare Sichtfeld dadurch leicht reduziert wird.
Die Debug-Option "-dbg" fügt dem Video zusätzliche Overlays hinzu, um die Verschiebung sichtbar zu machen und deren Korrekturen anzuzeigen.
Ein generiertes Video mit Debug-Overlays. Es wird deutlich, wie die Bildverschiebung kompensiert wird. Die Position des inneren Bildes wird durch grüne Overlays markiert. Die Wahre Bildmitte wird mit einem blauen Fadenkreuz angezeigt. Im Verlauf von mehreren Zoomschritten werden sich die grünen Markierungen immer mehr dem Zentrum annähern. Bei jedem Bildwechsel werden sie zurück gesetzt.Rendern von Spiralgalaxien.
Datenschutzkonforme Verwendung von Karten des OpenStreetMap-Projektes in eigene Webseiten.

Menschenleere Naturfotos auch an belebten Plätzen machen dank YOLOv7 und OpenCV.

Das magnetische Pendel simuliert die chaotische Interaktion eines Pendels mit drei Magneten.