
Kunstwerke aus Punkten. Über die fast vergessene Kunst der Farbreduktion von Computergrafiken.

Die beste Software, die ich nie geschrieben habe
 Stjörnhorn — ein knotenbasierter Editor für Bild-, Video- und Datenverarbeitung. Das gesamte Projekt entstand
kompromisslos mit KI-Unterstützung, für Programmierung, Assets und Dokumentation.
Stjörnhorn — ein knotenbasierter Editor für Bild-, Video- und Datenverarbeitung. Das gesamte Projekt entstand
kompromisslos mit KI-Unterstützung, für Programmierung, Assets und Dokumentation.
Jeder Softwareentwickler hat einen Stapel an Projektideen, die nie verwirklicht werden. Eines der Projekte auf meinem Stapel heißt OCVL. Es sollte für OpenCV Vision Library stehen. Ein High-Level-Wrapper der OpenCV-Bibliothek für Bildbearbeitung. Die Bibliothek sollte alles können, von einfachen Filteroperationen über das vollautomatische Stapeln von Astrofotos bis hin zum kamerabasierten Datenlogger für digitale Anzeigen aller Art.
Sie konnte all das, aber was ich nicht konnte, war, das Projekt zu Ende zu führen und eine wiederverwendbare Basis zu schaffen. Sobald ein Problem wie Astrostacking oder ein OCR-basierter Datenlogger gelöst ist, wird es langweilig. Der Rest sind API-Aufräumarbeiten, das Schreiben von Dokumentationen und der Bau einer Benutzeroberfläche – alles andere als spannend. Das Gegenteil von Spaß. Solche Aufgaben erledige ich im Job, aber nicht in der Freizeit. Am Ende stand die Designidee eines knotenbasierten Ablaufs, der es erlaubt, Filter und Bearbeitungsschritte aneinanderzureihen und zu erweitern. Es fehlte jedoch die Zeit, um das in einer Anwendung zusammenzuführen. Die Entwicklung eines solchen Freizeitprojektes würde sich über Jahre hinziehen.
Auf der anderen Seite wollte ich ohnehin einen Artikel über generative KI schreiben. Warum also nicht beides kombinieren? Das ist also die Geschichte von Stjörnhorn, der besten Software, die ich nie geschrieben habe.

Stjörnhorn ist ein Knotenbasierter Floweditor für die Bearbeitung von Bildern, Videos und Daten.Vorkompilierte Binärarchive für Windows und Linux können über GitHub heruntergeladen werden.
Der Begriff Vibe Coding kam Anfang 2025 auf und beschreibt eine Art, mit großen Sprachmodellen Software zu schreiben: Man beschreibt einem KI-Assistenten, was man möchte, akzeptiert die generierten Vorschläge weitgehend ungeprüft und korrigiert nur dort, wo das Ergebnis nicht der eigenen Erwartung entspricht. Das Ziel ist nicht, jede Zeile zu verstehen, sondern eine Idee in lauffähigen Code zu überführen.
"There's a new kind of coding I call 'vibe coding', where you fully give in to the vibes, embrace exponentials, and forget that the code even exists."
— Andrej Karpathy, Februar 2025
Für viele Softwareentwickler ist Vibe Coding allerdings ein abstoßendes Konzept. Ein Prozess, um automatisiert seelenlosen, minderwertigen und letztendlich unwartbaren Code zu erstellen. Mit einem System, das vermutlich weitgehend mit dem Quellcode des "Durchschnittsprogrammierers" auf GitHub trainiert wurde — aber was, wenn es funktioniert?
Wie bereits erwähnt, ist der Startpunkt meine unveröffentlichte OCVL-Bibliothek. Das sind 2500 Zeilen Code in 32 Dateien Python-Quellcode, an denen ich über eine Zeit von insgesamt 25 Monaten immer mal wieder gearbeitet habe. Ich habe sie hauptsächlich in Projekten für diese Webseite verwendet. OCVL-Code befindet sich im Touristenfilter, im Endlos-Zoom-Effekt, in einem undokumentierten visuellen Datenlogger und zuletzt auch im Archiv des Dithering-Artikels.
Der Plan war, jede Möglichkeit der KI-Unterstützung zu nutzen — ohne Einschränkungen, ohne Reue. Das Projekt sollte plattformunabhängig sein, auf einem einfachen Python-Stack basieren und einen grafischen Knoteneditor haben. Ich wäre nur ein Projektmanager, der Architekturvorgaben macht.
Die Umsetzung erfolgte mit Claude Opus 4.6 1M und 4.7 1M. Das sind Modelle mit 1 Million Tokens Kontextfenster. Das ist wichtig, denn wenn man der KI einen Prompt sendet, dann wird intern nicht nur der Prompt übermittelt, sondern auch weite Teile des bisherigen Gesprächsverlaufes und relevante Dateien aus dem Projekt. Je mehr Kontext die KI hat, desto besser kann sie die Aufgabe verstehen und umsetzen.
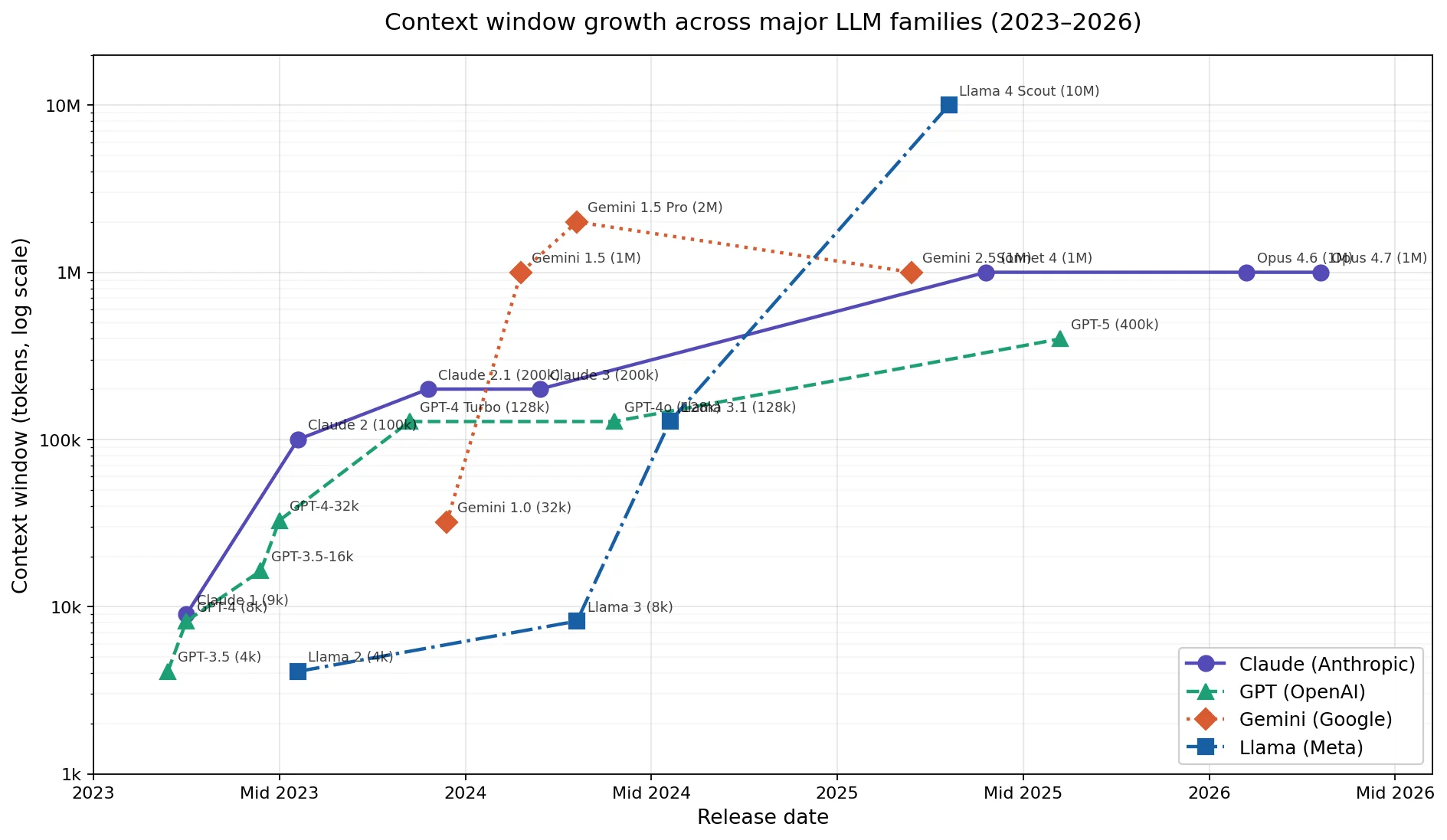 Zunahme der Kontextfenstergrößen verschiedener Sprachmodelle 2023-2026. (Logarithmische X-Achsenskalierung)
Zunahme der Kontextfenstergrößen verschiedener Sprachmodelle 2023-2026. (Logarithmische X-Achsenskalierung)
Heute erscheint eine Million Token Kontextspeicher noch groß, ChatGPT 3.5-turbo fing im Jahr 2023 mit gerade einmal 4096 an. In zwei Jahren wird auch das wenig sein.
Ein Sprachmodell ist ein Werkzeug, aber auch ein Mitarbeiter. Es ist wichtig, ihm eine Rolle zuzuweisen und es darin einzuweisen. Für Claude geschieht das mit der Datei Claude.md. Für dieses Projekt sollte die KI als Softwareentwickler agieren und auch selbständig auf Wartbarkeit des Quellcodes achten. Im Verlauf der Entwicklung habe ich es auch mit der Aufgabe betraut, die Dokumentation zu schreiben und Backlogs zu erstellen. Das Dokument wurde im Verlauf der Entwicklung immer mehr erweitert.
Lege immer eine Rollendefinition an und verweise dort auf etablierte Programmierprinzipien wie
SOLID. Ein expliziter Verweis darauf in
CLAUDE.md animiert das Modell zu sauberer, wartbarer Architektur, statt eine
Copy-und-Paste-Lösung mit dem geringsten Aufwand zu wählen.
Die Beiträge der KI wurden fast ausschließlich über sogenannte Pull-Requests (PR) in das Projekt integriert. Das heißt, die KI hat nicht direkt am Hauptzweig gearbeitet, sondern ihre Änderungen in einem separaten Branch umgesetzt. Dieser wurde dann von mir überprüft und in den Hauptzweig überführt. Das ist ein etablierter Prozess in der Softwareentwicklung. Er hatte den Vorteil, dass ich die Kontrolle über die Änderungen behalten konnte und gleichzeitig die KI frei arbeiten lassen konnte. Änderungswünsche habe ich in der Regel direkt mit der KI besprochen.
 Die Claude CLI ist eine der Möglichkeiten, mit dem Programmierassistenten zu interagieren. Sie hat Vorteile, wenn
man lokal arbeitet, beispielsweise kann man mit ihr zwei Projektverzeichnisse vergleichen.
Die Claude CLI ist eine der Möglichkeiten, mit dem Programmierassistenten zu interagieren. Sie hat Vorteile, wenn
man lokal arbeitet, beispielsweise kann man mit ihr zwei Projektverzeichnisse vergleichen.
Das Projekt beginnt mit einem leeren Git-Repository und im Benutzerinterface von Claude Code. Tatsächlich habe ich meistens mit der Webseite gearbeitet. Die CLI ist zwar praktisch für das lokale Arbeiten, aber ich wollte Kontrolle über den Entwicklungsprozess ausüben und habe daher auf ein Entwicklungsmodell ausschließlich mit Pull-Requests gesetzt. Das geht zwar prinzipiell auch mit der CLI, aber diese würde Branches und Pull Requests unter meinem Account anlegen und könnte auch versehentlich direkt in den Hauptzweig pushen.
Das Arbeiten mit Pull-Requests erlaubt es, den Ursprung einer Änderung nachzuvollziehen und zumindest theoretisch die Kontrolle über alle Änderungen zu behalten.
Praktisch wird man schon nach kurzer Zeit merken, dass die Qualität der Zuarbeiten sehr hoch ist und man häufig Änderungen durchwinkt. Das ist definitiv nicht der Durchschnittsprogrammierer, den ich erwartet hätte. Es ist ein sehr guter Programmierer. Einer, der wie ein menschlicher Entwickler Daten benötigt, um Fehler zu beheben. Aus diesem Grund ist es ratsam, der KI zu sagen, dass sie von Anfang an einen Logger einbauen soll. Damit kann sie später Programmabläufe nachvollziehen und bekommt Informationen, um Fehler systematisch zu analysieren.
Beauftrage die KI, von Anfang an einen Logger in das Programm einzubauen, und lasse sie ebenfalls einen Crash-Handler für Abstürze in nativem Code anlegen. Wenn ein Bug auftritt, liefert das Log der KI genau den Kontext, den sie braucht, um das Problem systematisch zu analysieren.
Um die Komplexität des Projektes im Griff zu behalten, ist eine weitere Praxis der Softwareentwicklung, regelmäßig Refactoring-Sessions einzulegen. Damit das funktioniert, sollte man eine Test-Suite haben. Auch diese kann eine KI schreiben und vollautomatisch erweitern.
Lass die KI von Anfang an Unit-Tests für neue Funktionen schreiben. Praktisch musst du ihr nur einmal sagen, ein Unit-Test-Framework einzubauen, und sie in ihrem Rollenfile darauf hinweisen, selbständig Unit-Tests zu schreiben. Diese sind ein wichtiger Bestandteil der Qualitätssicherung und helfen, Regressionsfehler zu vermeiden. Sie geben der KI darüber hinaus ein Beispiel für die Verwendung einer Funktion, was die Wahrscheinlichkeit erhöht, dass sie diese Funktion in Zukunft korrekt verwendet.
Was bleibt, ist den Technologiestack zu wählen und die KI mit der Umsetzung zu beauftragen. Für Stjörnhorn war Python und OpenCV gesetzt. Das UI-Toolkit war zunächst DearPyGui, aber nach kurzer Zeit bin ich auf PySide6 umgestiegen. Das alles kann man in einem Prompt erledigen lassen:
Lege ein neues Projekt auf Basis von Python, OpenCV und PySide6 an. Es soll
ein knotenbasierter Editor für Bild- und Videoverarbeitung werden, in den
sich später meine bestehende OCVL-Bibliothek einbinden lässt.
Richte zusätzlich folgende Qualitätssicherung ein:
- Einen Logger, der wichtige Programmabläufe und Fehler in eine Logdatei schreibt.
- Eine Behandlung von Abstürzen in nativem Code, sodass auch diese im Log landen
und ich später nachvollziehen kann, was passiert ist.
- Ein Unit-Test-Framework mit ersten Tests für die Kernfunktionen.
Halte in der CLAUDE.md fest, dass neue Funktionen immer mit passenden Tests
geliefert werden sollen.Das ist nicht der Originalprompt, aber er würde funktionieren.
Geplant war die Erstellung einer Software für die Bearbeitung von Bildern und Videos mit einem knotenbasierten Editor. Eine Art "Photoshop für Nerds", die es ermöglicht, komplexe Bildverarbeitungsabläufe zu erstellen, ohne eine einzige Zeile Code schreiben zu müssen. Die Software sollte in mehrere Module aufgeteilt sein, wobei jedes Modul eine eigene Seite darstellt, zwischen denen man hin- und herschalten kann.
Die Module im Einzelnen:
Die KI sollte ebenfalls die Programmdokumentation erstellen und eine einfache CI/CD-Pipeline über GitHub Actions aufsetzen, denn das Projekt sollte so weit wie möglich automatisiert werden.
Das Projekt begann unter dem Namen "Image-Inquest" als Test mit der Erwartungshaltung, dass es ultimativ scheitern würde. Allerdings waren die Fortschritte von Anfang an erstaunlich. Begonnen wurde mit DearPyGui, einem einfachen UI-Toolkit, das sich gut für schnelle Prototypen eignet. Es wurde gewählt, weil es einen einfachen Knoteneditor mitbrachte. Ich hielt das für entscheidend, da ich der KI nicht zugetraut habe, einen eigenen zu implementieren und keine Drittanbieterkomponenten im Projekt wollte. 124 Commits und ungefähr 8-10 Stunden Entwicklungszeit später hatte das Projekt folgenden Stand:
 Eine leere Startseite, aber das Applikationsframework mit Modulaufteilung funktioniert bereits.
Eine leere Startseite, aber das Applikationsframework mit Modulaufteilung funktioniert bereits.
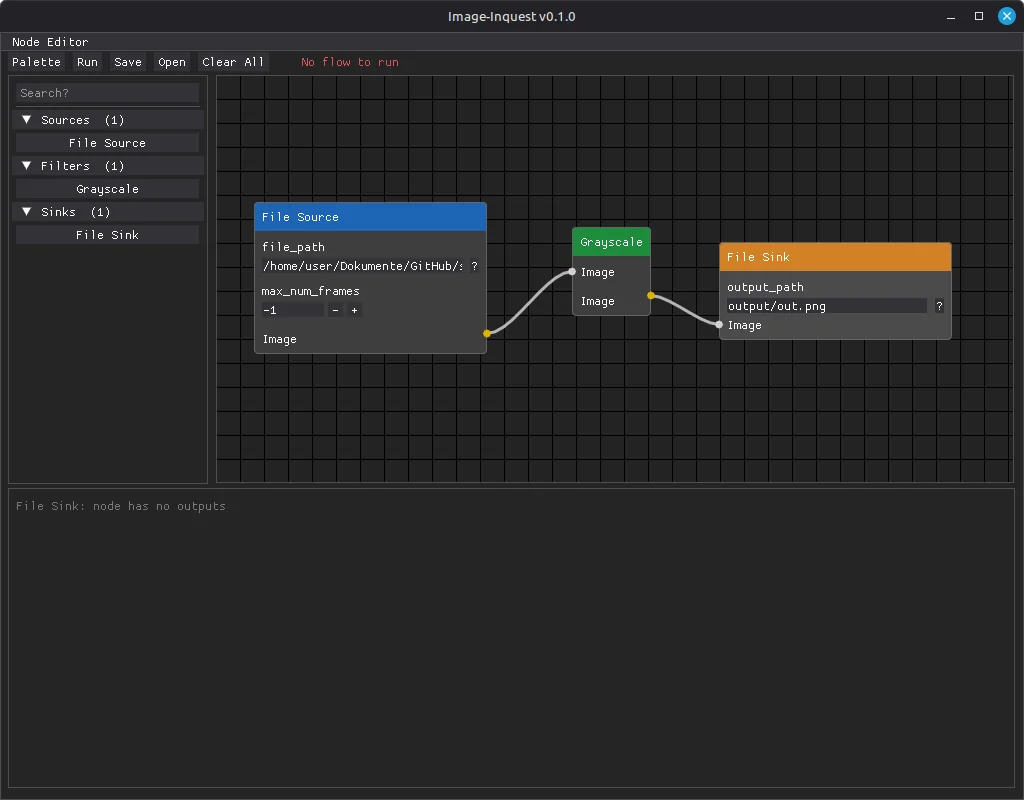 Der erste funktionsfähige Prototyp mit DearPyGui: Knoteneditor mit Knotenliste, Drag-and-Drop, allerdings noch
keine lauffähige Bildbearbeitungskette.
Das mythische Stjörnhorn, Symbolbild für die Sloppifizierung der Softwareentwicklung oder magischer Helfer?
Der erste funktionsfähige Prototyp mit DearPyGui: Knoteneditor mit Knotenliste, Drag-and-Drop, allerdings noch
keine lauffähige Bildbearbeitungskette.
Das mythische Stjörnhorn, Symbolbild für die Sloppifizierung der Softwareentwicklung oder magischer Helfer?
Es gab einen funktionierenden Knoteneditor mit einer Knotenliste, aus der per Drag and Drop Elemente in den Editor gezogen werden konnten. Es konnten Verbindungen zwischen den Bearbeitungsschritten erzeugt werden. Die Knoten wurden dynamisch geladen und enthielten bereits funktionsfähigen Code, den die KI vom OCVL-Projekt übernommen und angepasst hatte. Die Bearbeitungsschritte waren allerdings noch nicht funktionsfähig, sondern nur Platzhalter.
Um das noch einmal deutlich zu sagen: Das war der Stand nach einem Arbeitstag. Ab hier war klar, dass das Projekt nicht an den mangelnden Fähigkeiten der KI scheitern würde, denn auf dieser technologischen Basis hätte es weiterentwickelt werden können. Allerdings war auch klar, dass DearPyGui an seine Grenzen stieß.
Aus diesem Grund wurde das UI komplett auf PySide6 umgestellt. Nicht von mir, von der KI. Das war eine größere Umstellung, da PySide6 keinen Knoteneditor mitbrachte, aber die KI hat auch diese Aufgabe gemeistert und einen eigenen neu erstellt. Dieser sah von Anfang an besser aus als der von DearPyGui und war mit den Möglichkeiten der Qt-Lib leichter zu erweitern.
Jetzt brauchte das Projekt noch einen neuen Namen. Über Umwege wurde "Stjörnhorn" gewählt. Ans Altnorwegische angelehnt heißt es in etwa so viel wie "Sternenhorn". Es ist eine erfundene mythische Kreatur, die es eigentlich nicht geben kann. Ich fand das passend und es hatte 0 Treffer bei Google...
Zum Zeitpunkt des Schreibens dieses Artikels sind ungefähr 100 Stunden Entwicklungszeit in das Projekt geflossen. Das ist nicht viel für ein Softwareprojekt. Zeit für eine Bilanz.
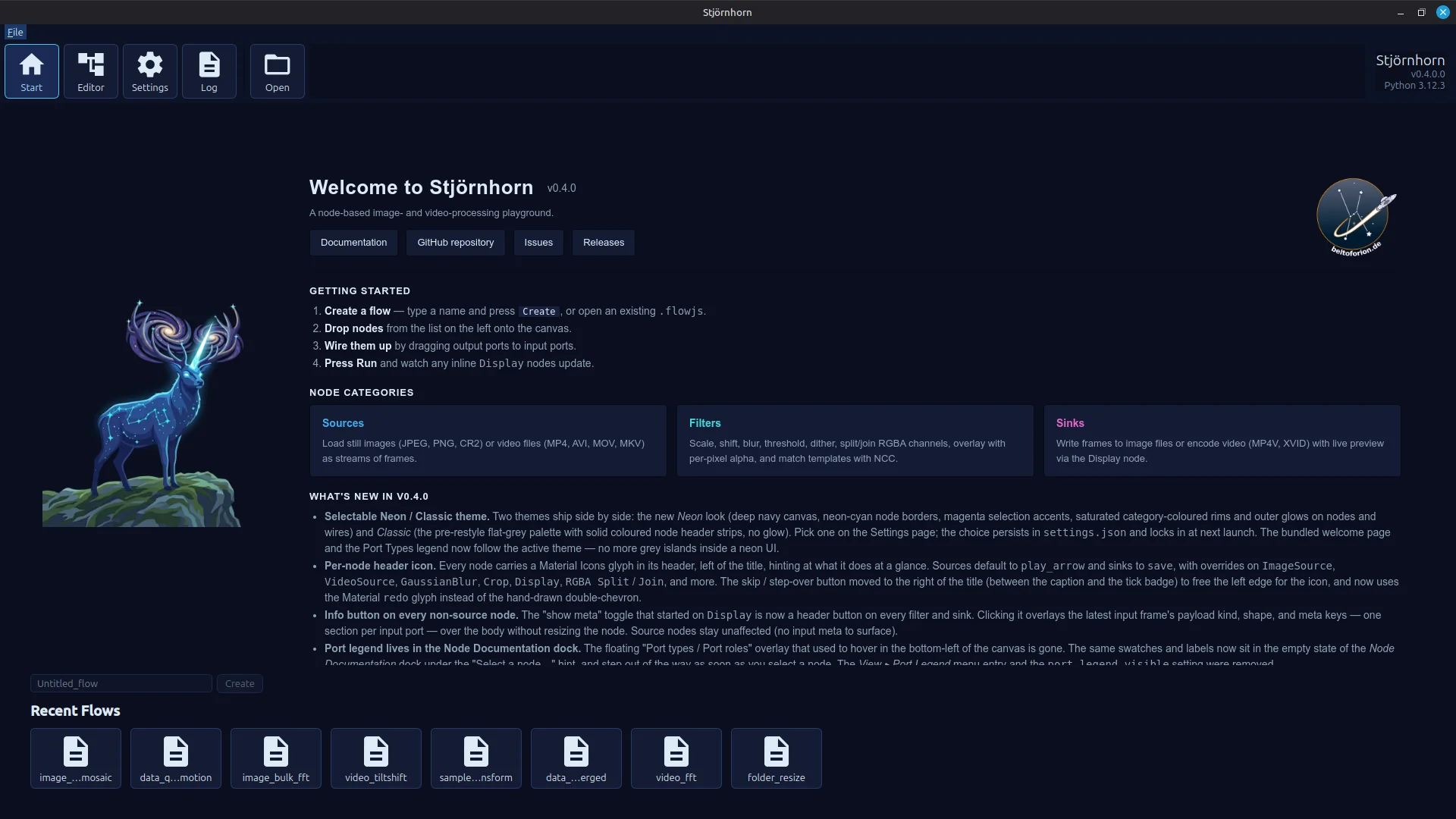 Startbildschirm mit Recently-Used-File-Liste und Webview-Element für die Anzeige einer Kurzdokumentation.
Startbildschirm mit Recently-Used-File-Liste und Webview-Element für die Anzeige einer Kurzdokumentation.
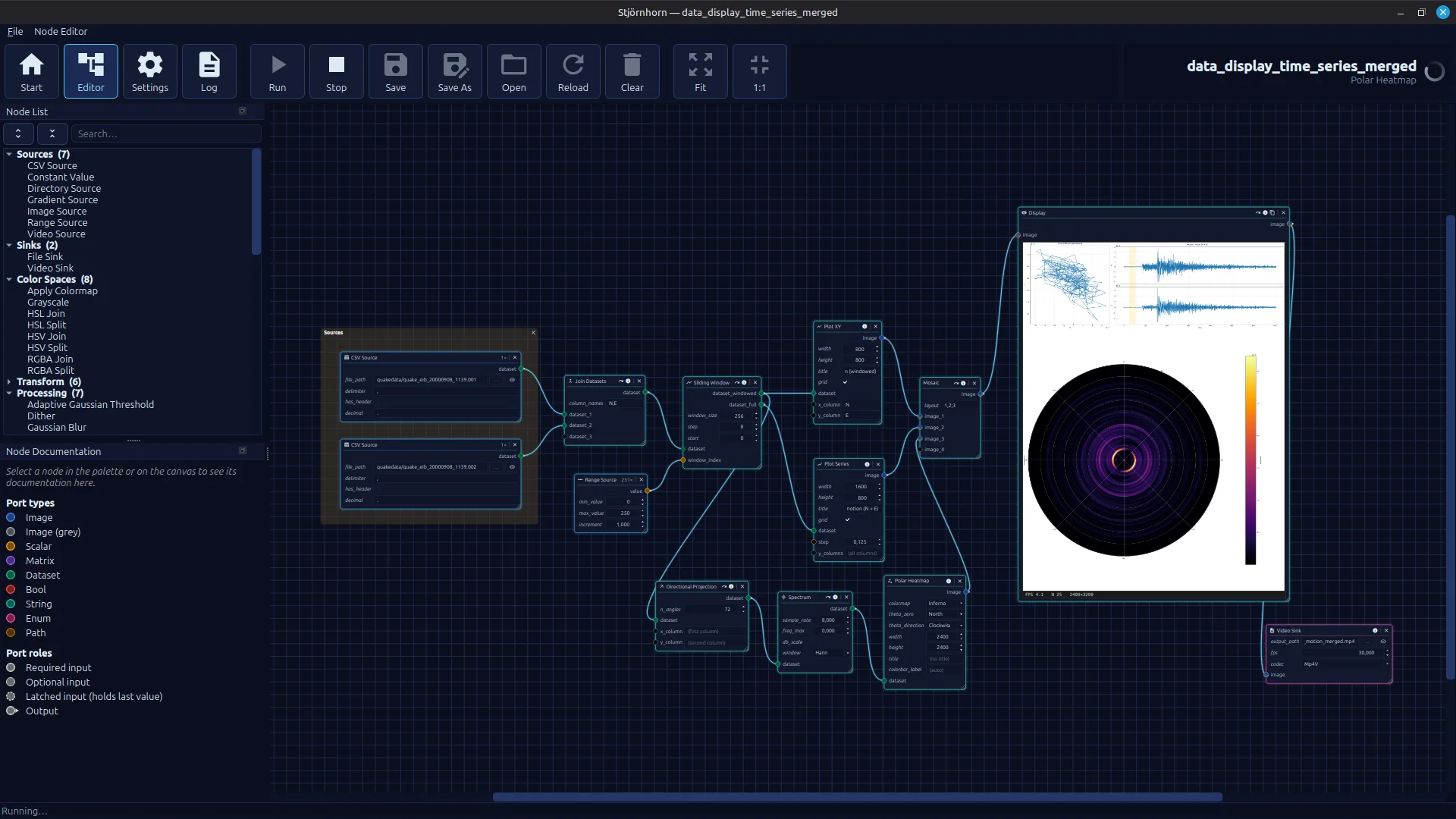 Ein funktionsfähiger Knoteneditor mit einer Vielzahl lauffähiger Abläufe. Im Bild wird aus Erdbebendaten ein
Hodogramm mit darunter liegender spektraler Heatmap gezeigt, die darstellt, in welche Richtung der Boden schwingt.
Das Ganze wird als Video ausgegeben.
Ein funktionsfähiger Knoteneditor mit einer Vielzahl lauffähiger Abläufe. Im Bild wird aus Erdbebendaten ein
Hodogramm mit darunter liegender spektraler Heatmap gezeigt, die darstellt, in welche Richtung der Boden schwingt.
Das Ganze wird als Video ausgegeben.
Jeder der mittlerweile über 50 verschiedenen Knoten ist dokumentiert. Die Dokumentation wird angezeigt, wenn er ausgewählt wird. Es gibt zusätzliche Funktionen im Header, um beispielsweise Daten zu inspizieren, und man kann Knoten ausblenden und so im Ablauf bestimmte Schritte überspringen. Es gibt Knotenparameter, welche wie Konstanten wirken, Input-Ports und Output-Ports. Für alle Datentypen gibt es spezifische UI-Elemente für deren Eingabe. Die Ports akzeptieren jetzt verschiedene Datentypen: Matrix, Skalar, Farbbilder, Graustufenbilder und Tabellendaten.
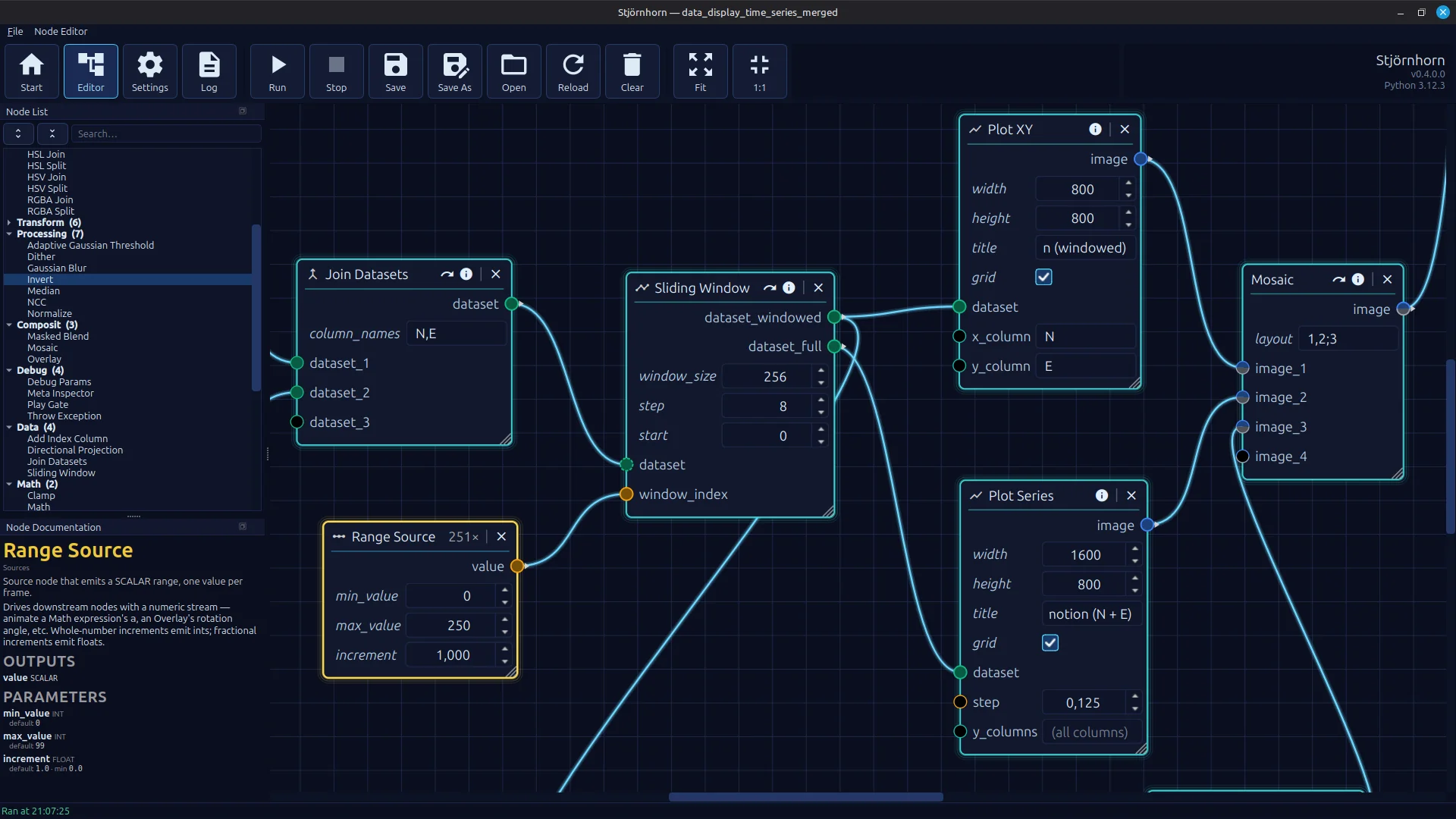 Ein funktionsfähiger Knoteneditor mit einer Vielzahl lauffähiger Abläufe. Im Bild wird aus Erdbebendaten ein
Hodogramm mit darunter liegender spektraler Heatmap gezeigt, die darstellt, in welche Richtung der Boden schwingt.
Das Ganze wird als Video ausgegeben.
Ein funktionsfähiger Knoteneditor mit einer Vielzahl lauffähiger Abläufe. Im Bild wird aus Erdbebendaten ein
Hodogramm mit darunter liegender spektraler Heatmap gezeigt, die darstellt, in welche Richtung der Boden schwingt.
Das Ganze wird als Video ausgegeben.
Die Benutzeroberfläche kann mit zwei verschiedenen Skins verwendet werden. Das hier gezeigte dunkelblaue Farbschema basiert auf einem KI-generierten Vorschlag für das Titelbild der Applikation. Die KI wurde einfach beauftragt, ein Farbschema zu erstellen, das ähnlich aussieht.
Im Verlauf der Entwicklung ergaben sich einige Fehlerfälle, die ausnahmslos von der KI beseitigt wurden. Es begann mit einem harten reproduzierbaren Absturz auf Windows-Systemen beim Anklicken von Menüpunkten. Für erfahrene Qt-Entwickler ist so etwas kein Problem. Für mich in der Rolle des "Vibecoders in Chief" ohne aktuelle Qt-Erfahrung wäre es aufwendiger geworden. Das Problem wurde jedoch durch "Caveman Debugging" mittels Logausgaben schnell durch die KI gefunden. Gelernt habe ich dabei allerdings nichts.
Das zweite Problem war komplizierter. Es war ein sporadischer, nicht reproduzierbarer Absturz beim Ausführen der Bildbearbeitungsketten. Wieder nur auf Windows-Systemen. Hier fehlte mir zunächst jeglicher Anhaltspunkt, aber ich hoffte, mit Post-Mortem-Debugging genug Informationen sammeln zu können, um die KI zu einer Lösung zu führen. Aus diesem Grund wurde zusätzlich zum Logging ein Crashhandler im Programm eingebaut (natürlich nicht von mir), um wenigstens irgendeine Fehlermeldung mit dazugehöriger Aufrufliste zu erhalten.
Probleme dieser Art sind bösartiger. Sie treten sporadisch auf und der Horror, der den Vibe Coder ergreift, wenn er sich mit der Möglichkeit konfrontiert sieht, das Problem selbst verstehen zu müssen, ist real. Ich war allerdings wild entschlossen, es nicht so weit kommen zu lassen, und griff auf die Allzweckwaffe des Vibe-Coding zurück: Copy und Paste eines ungelesenen Crashreports direkt in den Prompt mit der unmissverständlichen Aufforderung: Fix this!.
Es hat geholfen. Die Ursache war offenbar, dass numba, der in Stjörnhorn verwendete Just-in-Time-Compiler, Teile des Codes im Hauptthread kompilieren muss. Dass die KI das herausfindet, war für mich überraschend. Das Problem wurde dadurch gelöst, dass numba ein Warmup macht, indem es den Code im Hauptthread kompiliert, bevor er in einem anderen Thread ausgeführt wird.
Es gab noch ein paar kleinere Probleme, aber nichts, was nicht mit einem "Fix this!" und einem in das Chatfenster kopierten Logfile-Auszug gelöst werden konnte.
Blicken wir auf die Statistiken nach ungefähr 100 Stunden Entwicklungszeit. Auf meinen Namen laufen lediglich 7% der Codezeilen. Aber auch das ist irreführend, denn diese Zeilen sind mit Sicherheit auf den Quellcode der OCVL-Bibliothek zurückzuführen, welche ich als Referenz im Repository abgelegt habe. Das ist passiver Code, der nicht verwendet wird und nur als Vorlage dient. Wenn man das herausrechnet, dürfte mein Beitrag bei maximal 1-2% liegen. Ich kann mich nicht erinnern, überhaupt etwas direkt zur Codebasis beigetragen zu haben. Ich wollte hier auch nicht Programmierer sein, ich wollte Softwarearchitekt sein.
 Einige Basismetriken des Projektes im Überblick.
Einige Basismetriken des Projektes im Überblick.
Das Ergebnis nach ungefähr zwei Wochen Netto-Entwicklungszeit: 46600 Zeilen Quellcode netto erstellt, wovon im Projekt 34000 erhalten geblieben sind. Die KI hat 219 Pull Requests erstellt, was im Mittel 10 pro Tag bedeutet.
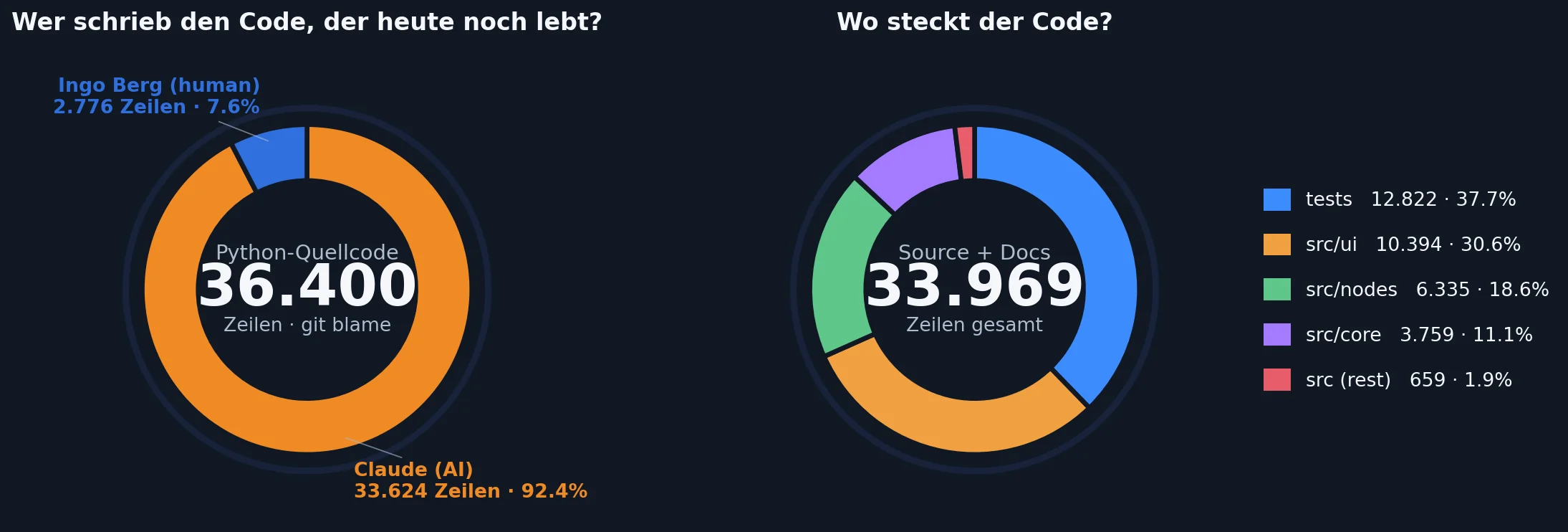 Wer hat den Code wirklich geschrieben und wie verteilt er sich über das Projekt?
Wer hat den Code wirklich geschrieben und wie verteilt er sich über das Projekt?
Der kumulative Netto-Codezuwachs zeigt eine hohe Aktivität mit rasantem Zuwachs. Gegen Ende des Testzeitraumes habe ich den Fokus verstärkt auf Refactoring gelegt. Das erklärt die Zunahme an entfernten Zeilen.
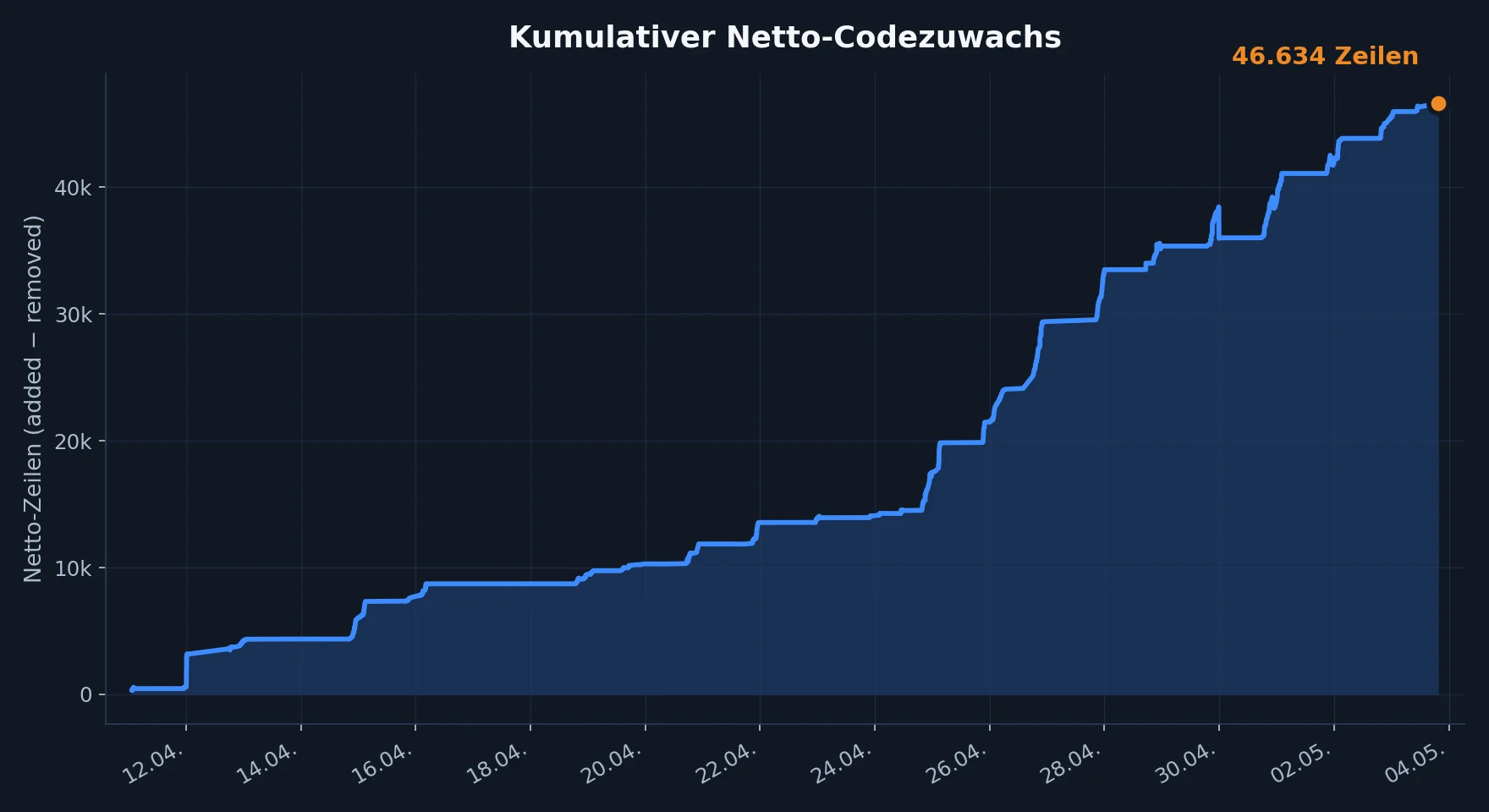 Kumulativer Netto-Codezuwachs über der Zeit. Am Ende blieben nicht alle Zeilen im Projekt, denn
in Refactoring-Sessions wurden auch Zeilen gelöscht.
Kumulativer Netto-Codezuwachs über der Zeit. Am Ende blieben nicht alle Zeilen im Projekt, denn
in Refactoring-Sessions wurden auch Zeilen gelöscht.
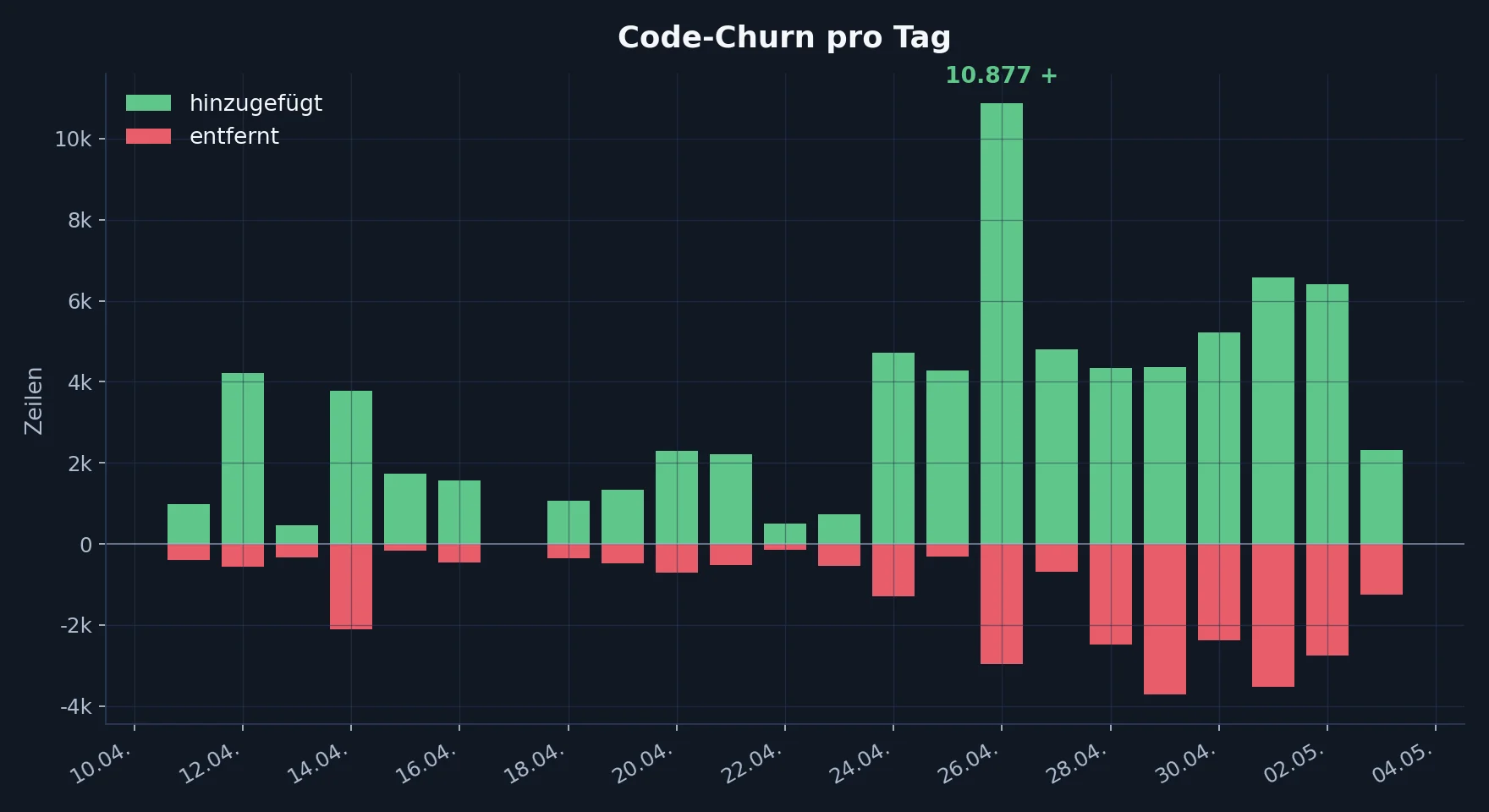 Code-Churn pro Tag. Zeigt, wie viele Zeilen Code täglich geändert wurden.
Code-Churn pro Tag. Zeigt, wie viele Zeilen Code täglich geändert wurden.
Die Stabilität in der Entwicklung wurde nicht zuletzt durch eine umfassende Test-Suite erreicht, die von der KI selbständig erweitert wurde. Es gibt über 760 Unit-Tests, die alle automatisch ausgeführt werden, wenn die KI Quellcode generiert. Ich habe ungefähr 3 dieser Tests explizit angefordert, die restlichen wurden von der KI selbständig erstellt.
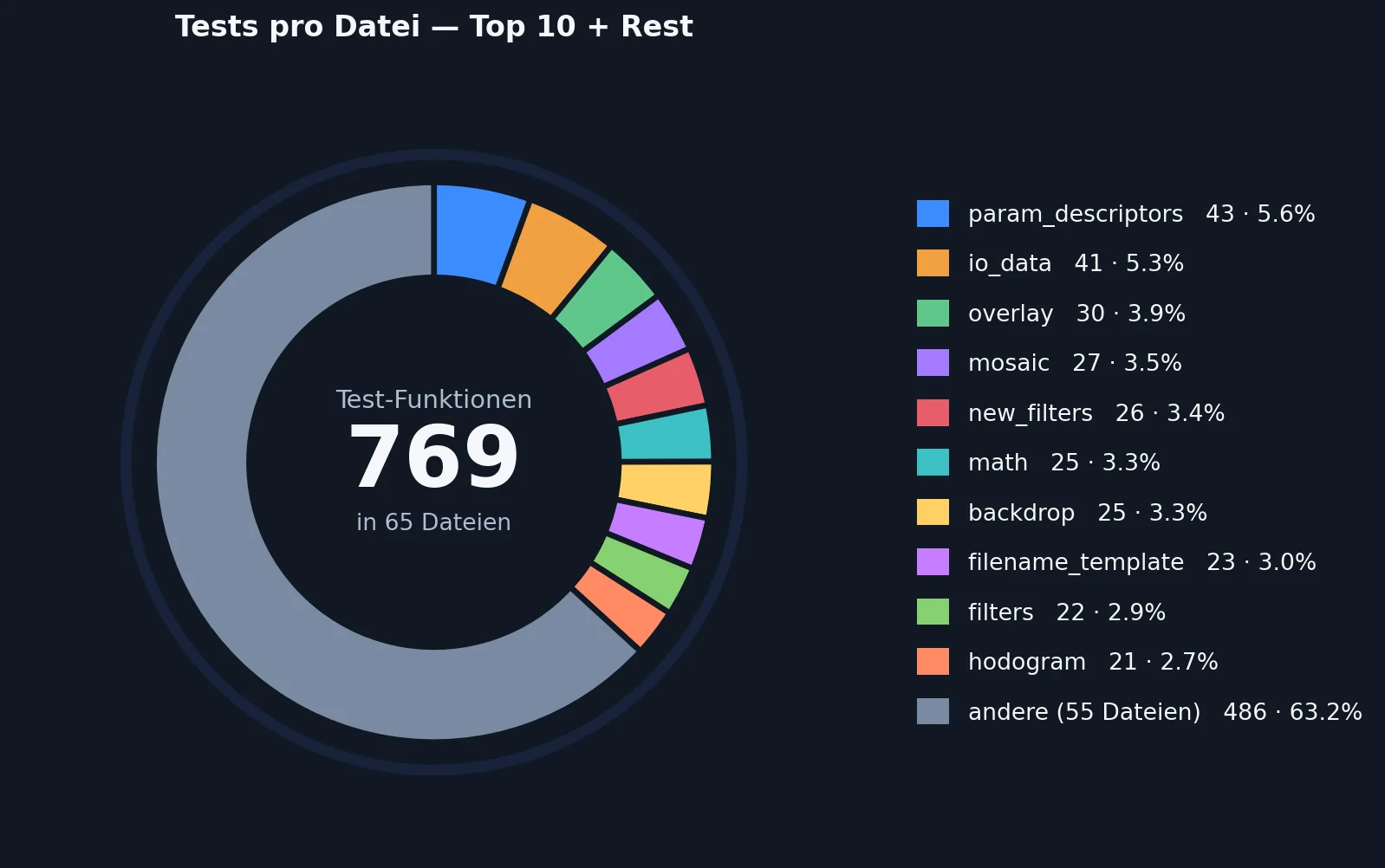 Übersicht der Test-Suite. Zeigt die Anzahl der Unit-Tests und deren Verteilung im Quellcode.
Übersicht der Test-Suite. Zeigt die Anzahl der Unit-Tests und deren Verteilung im Quellcode.
Was ich hier gemacht habe, war eher "betreutes" Vibe Coding und das kann funktionieren. Der aktuelle Projektstand ist in puncto UI und UX besser als das, was ich traditionell im gleichen Zeitraum hätte erstellen können. Zeit, die ich beim Programmieren eingespart habe, konnte ich beim UX-Design investieren, ohne mir Gedanken über die handwerkliche Umsetzung zu machen.
Ich habe während der Entwicklung immer wieder auf den Punkt gewartet, an dem die KI den Überblick verliert und mir eine Codebasis übergibt, die so unverständlich ist, dass ich sie nicht mehr warten kann. Das ist nicht passiert. Zum einen hat sie den Überblick nicht verloren, zum anderen habe ich dafür gesorgt, zumindest die Architektur übersichtlich zu halten. Ich kenne die Codebasis von Stjörnhorn nicht in jedem Detail, aber ich verstehe die Architektur und die prinzipiellen Abläufe. Dennoch bin ich der Meinung, dass es für mich ein erheblicher Aufwand wäre, in allen Teilen der Software den kompletten Überblick zu erlangen.
Software hat einen Lebenszyklus und an dessen langem Ende stehen kontinuierliche Wartung und ständige Erweiterungen. Die KI generiert schlechten Code genauso schnell wie guten. Es ist aber anstrengend, ständig große Mengen an maschinengeneriertem Code zu überprüfen, und mit der Zeit wird man dazu übergehen, die Änderungen ungesehen durchzuwinken. Das ist eine Gefahr, denn wer das macht, wird mit einer für Mensch und Maschine unwartbaren Codebasis enden.
 Ein Symbolbild, aber vermutlich nicht weit entfernt von den Gedankengängen vieler Manager von Softwareprojekten. Wie viele Token erhalte ich, wenn ich den Juniorprogrammierer einspare?
Ein Symbolbild, aber vermutlich nicht weit entfernt von den Gedankengängen vieler Manager von Softwareprojekten. Wie viele Token erhalte ich, wenn ich den Juniorprogrammierer einspare?
Blicken wir auf die Kosten. Die Währung, in der man KI bezahlt, ist das Token. Ein Token entspricht ungefähr einem kurzen Wort. Der Preis einer Anfrage ergibt sich aus ihrer Datenmenge. Diese setzt sich aus der Anfrage selbst und dem mitgelieferten Kontext zusammen. Im Kontext ist die gesamte bisherige Konversation enthalten, aber auch große Teile des Quellcodes, der für die Problembearbeitung notwendig ist.
Das hier verwendete KI-Modell war Anthropics Claude Code mit dem Max-Abo. Dieses Abo bietet die 5-fache Tokenmenge des Standard-Abos. Damit konnte ich ohne Einschränkungen arbeiten. Es ist davon auszugehen, dass diese Abos trotz des vergleichsweise hohen Preises (ca. 100 Euro pro Monat) von Anthropic subventioniert werden, um Marktanteile zu gewinnen.
Bei Tests in meinem beruflichen Umfeld mit einem weitaus größeren Projekt als Stjörnhorn wurde das Inklusivvolumen eines Standard-Abos in unter einer Stunde mit nur wenigen Anfragen verbraucht. Für ein großes Projekt entstehen meiner Schätzung nach pro Tag Zusatzkosten von mindestens 30-100 Euro pro Entwickler nur für Tokens. An einem normalen Arbeitstag wurden von mir beispielsweise 18 Millionen Token verbraucht. Das kann schnell zu einem erheblichen Kostenfaktor werden.
Die neuen Werkzeuge sind Multiplikatoren, die bei erfahrenen Programmierern stärker wirken, denn eine falsch formulierte Frage verbraucht genauso viele Tokens wie eine zielführende. Deshalb wird sich in unmittelbarer Zukunft KI-unterstützte Softwareentwicklung negativ auf die Aussichten von Berufseinsteigern auswirken. Manager werden in jedem Juniorprogrammierer nur ein wandelndes Tokenbudget sehen, das man durch Nichteinstellung freisetzen kann. Aber wer jetzt verhindert, dass neue Softwareentwickler Erfahrung sammeln können, der wird in zwei Jahren niemanden haben, der in einer gigantischen Menge von KI-generiertem Code noch den Überblick behält.
Kunstwerke aus Punkten. Über die fast vergessene Kunst der Farbreduktion von Computergrafiken.

Erstellen von Fraktalen mittels sich rekursiv selbst aufrufender Funktionen.
Wie man mit einfachen Regeln Evolution mit dem Computer simulieren kann.

Wie man einen "Endlos-Zoom-Effekt" für ein Video aus einer Sequenz von KI-generierten Bildern erstellt.